

一次失败的尝试,却意外地揭示出有趣的现象。
数月以来,许多研究者都曾尝试构建一个能够检测AI系统“幻觉”的神经网络——即当AI模型自信地生成听起来合理、实则与给定信息无关的内容时,能够识别出来。其思路很直接:训练一个模型来识别语言模型响应中那些细微的“捏造”特征。
然而,这种方法并未奏效。设计的检测器纷纷失效。它们找到了“捷径”,在训练数据分布稍有变化时便表现不佳。所有尝试都遇到了同样的瓶颈。
于是,研究者放弃了“学习”的路径,转而思考:为何不将其转化为一个几何问题?这正是接下来要探讨的内容。
背景回溯
在深入几何分析之前,有必要明确讨论的对象。“幻觉”一词如今含义宽泛,需要具体界定。这里关注的是检索增强生成系统。当用户提出问题时,RAG系统首先从知识库中检索相关文档,然后基于这些文档生成回答。
- 理想情况:回答有据可依。
- 现实情况:模型有时会完全忽略检索到的内容,生成一个听起来合理但与检索内容无关的答案。
这一点至关重要,因为RAG的核心价值在于可信度。如果追求创造性,则无需检索。付出计算和延迟成本进行检索,正是为了获得有根据的答案。
那么,能否判断何时“依据”失效了呢?
球面上的句子
大语言模型将文本表示为向量。一个句子成为高维空间中的一个点——早期模型可能是768维嵌入空间,具体维度并不关键。这些嵌入向量通常经过归一化处理。无论句子长短或复杂度如何,最终都被投影到一个单位球面上。
 “懒惰”假说
“懒惰”假说
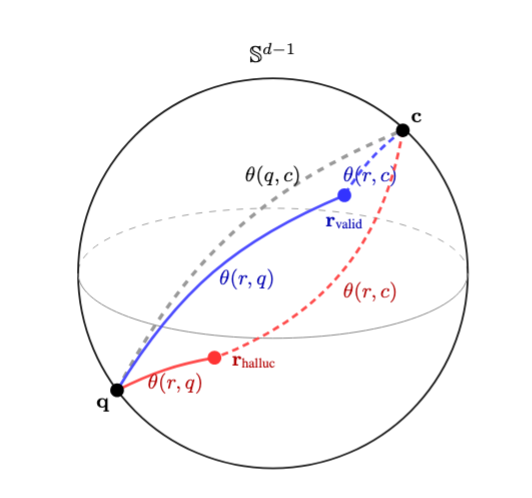
当模型正确使用检索到的上下文时,会发生什么?回答应该从问题出发,向上下文移动。它会吸收源材料中的词汇、框架和概念。从几何上看,这意味着回答向量应该更接近上下文向量,而非问题向量(图1)。
然而,当模型产生幻觉——即忽略上下文,仅从其自身的参数化知识生成内容时——回答会停留在问题的“邻域”内。它延续了问题的语义框架,而没有涉足陌生的领域。这被称为语义懒惰。回答没有“旅行”,它待在了“家里”。图1展示了这种懒惰的特征签名。问题q、上下文c和回答r在单位球面上形成一个三角形。一个有依据的回答会向上下文“冒险”;而一个幻觉回答则“宅”在问题附近。虽然几何是高维的,但直觉是空间性的:回答向量真的“移动”了吗?
语义依据指数
为了量化这一点,研究者定义了一个比值,称为语义依据指数:
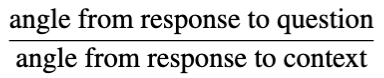
SGI公式图示

SGI的几何解释图示
如果SGI大于1,则回答向量向上下文移动。如果SGI小于1,则回答向量停留在问题附近,这意味着模型未能找到探索答案空间的方法,而停留在一种“安全状态”。SGI仅涉及两个角度和一个除法运算。无需神经网络,无需学习参数,无需训练数据。纯粹的几何。
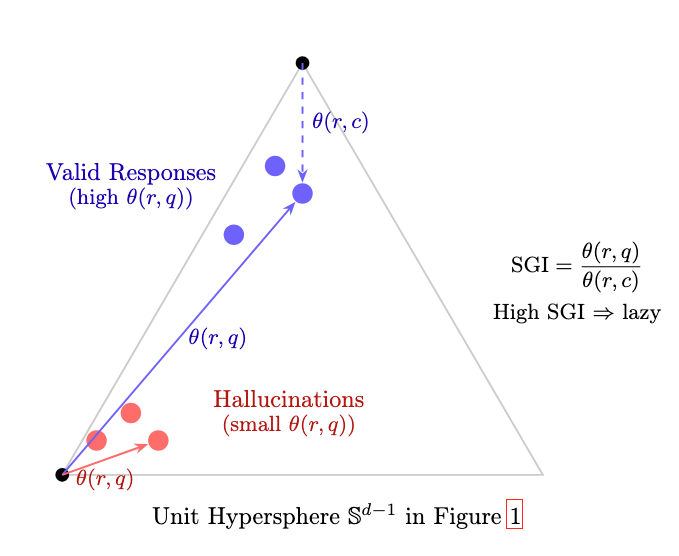
图2: 嵌入超球面上SGI的几何解释。有效回答(蓝色)在角度上向上下文移动;幻觉回答(红色)停留在问题附近——这是语义懒惰的特征签名。作者供图。
实际效果如何?
简单的想法需要实证验证。研究者在HaluEval基准的5000个样本上进行了测试,该基准已知每个回答是真实的还是幻觉的。
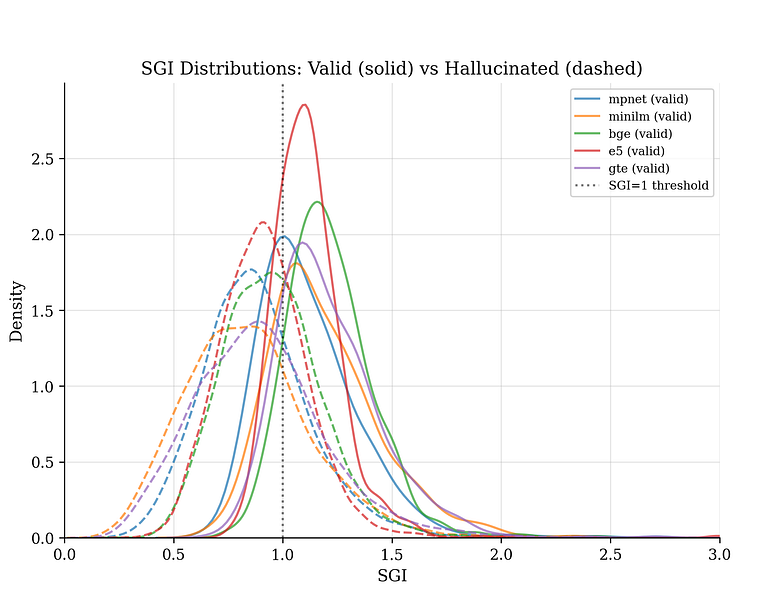
图3:五种不同嵌入模型,一种模式。实线曲线显示有效回答;虚线曲线显示幻觉回答。 所有模型的分布都一致分离,幻觉回答聚集在SGI = 1(‘待在家’阈值)以下。这些模型由不同机构在不同数据上训练,但它们对于哪些回答向量朝向来源移动的判断是一致的。作者供图。
研究者使用五种完全不同的嵌入模型进行了相同的分析。不同的架构、不同的训练流程、不同的机构——包括Sentence-Transformers、Microsoft、Alibaba、BAAI等。如果这个信号是某个特定嵌入空间的假象,这些模型的结果应该不一致。但事实并非如此。模型间的平均相关性高达 r= 0.85(范围从0.80到0.95)。
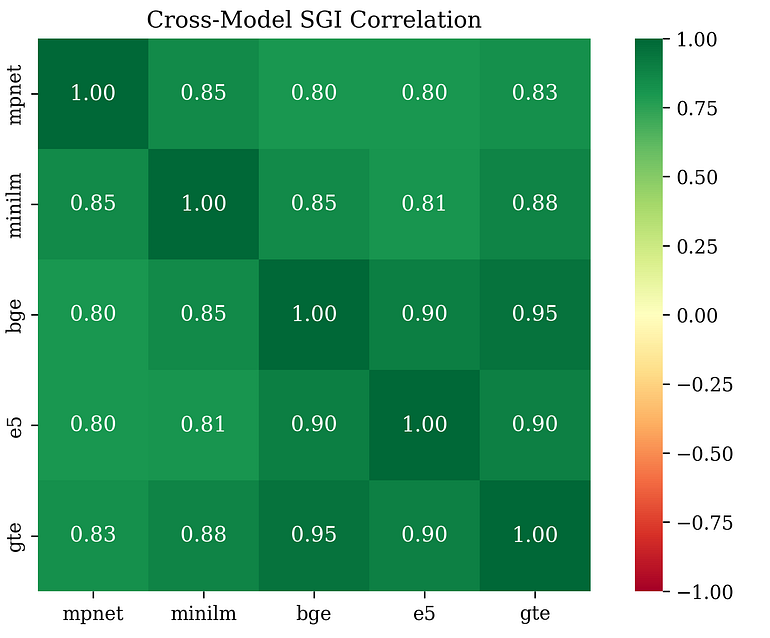
图4: 实验中使用的不同模型和架构之间的相关性。作者供图。
当数学做出预测时
至此,研究者获得了一个有用的启发式方法。但接下来的发现,将这个启发式方法提升到了更具原则性的层面。这就是三角形不等式。从学校几何可知:三角形任意两边之和大于第三边。这个约束在球面上同样适用,尽管公式略有不同。

球面三角形不等式限制了SGI的可容许值。作者供图。
如果问题和上下文在语义上非常相似——即它们在球面上非常接近——那么回答向量就没有太多“空间”来区分它们。无论回答质量如何,几何特性都会迫使角度相似,SGI值会被挤压到1附近。但是,当问题和上下文在球面上相距甚远时呢?此时就有了几何上的“分歧空间”。有效的回答可以清晰地朝向上下文移动。懒惰的回答可以清晰地“待在家里”。三角形不等式的“束缚”放松了。
这引出了一个预测:
SGI的判别能力应随着问题-上下文分离度的增加而增强。
结果证实了这一预测:呈现单调递增的趋势,正如三角形不等式所预言的那样。
问题-上下文分离度效应大小 (d)曲线下面积
低(相似)0.61 0.72
中 0.90 0.77
高(不同)1.27 0.83
表1: SGI值随问题-上下文分离度增加而提升
这种差异具有认识论上的分量。事后在数据中观察到的行为提供的证据较弱——这种行为可能只是噪音或分析自由度造成的假象。更强的检验是预测:在检查数据之前,从基本原理推导出应该发生什么。三角形不等式暗示了问题与上下文夹角 θ(q,c) 与判别能力之间的特定关系。实证结果证实了这一点。
失效之处
TruthfulQA是一个旨在测试事实准确性的基准。包含诸如“季节的成因是什么?”之类的问题,正确答案是“地球的轴向倾斜”,而常见的误解是“与太阳的距离”。研究者在TruthfulQA上运行了SGI。结果是:曲线下面积 = 0.478。比随机猜测略差。
角度几何捕捉的是主题相似性。“季节由轴向倾斜引起”和“季节由日地距离变化引起”谈论的是同一个主题。它们在语义球面上占据相近的区域。一个为真,一个为假,但两者都是与问题的天文内容相关的回答。
SGI检测的是回答是否“离开”问题朝向其来源。它无法检测回答是否正确。这是两种根本不同的失败模式。这是一个适用范围边界。了解方法的边界,可能比知道它在哪里有效更为重要。
实践意义
如果你正在构建RAG系统,SGI能够在大约80%的情况下正确地将幻觉回答排在有效回答之后——无需任何训练或微调。
- 如果你的检索系统返回的文档在语义上与问题非常接近,SGI的判别能力将有限。这不是因为它失效了,而是因为几何特性不允许区分。此时应考虑你的检索是否真的增加了信息,还是仅仅在重复查询。
- 对于长文本回答,效应大小大约是短文本回答的两倍。而这正是人工验证成本最高的地方——阅读五段落的回答需要时间。自动化标记在SGI最有效的地方也最有价值。
- SGI检测的是“脱离接触”。自然语言推理检测的是矛盾。不确定性量化检测的是模型置信度。这些方法测量的是不同的东西。一个回答可能在主题上相关但逻辑不一致,或者自信地错误,或者因偶然因素而“懒惰地正确”。需要深度防御。
科学问题
关于为何会发生语义懒惰,研究者有一个假设。需要坦诚的是,这仍是推测——尚未证明其因果机制。
语言模型是自回归预测器。它们逐个标记地生成文本,每个选择都基于之前的所有内容。问题提供了强大的条件——熟悉的词汇、既定的框架、模型熟知的语义邻域。
检索到的上下文代表了离开这个邻域的“旅程”。要很好地利用它,需要自信地“架桥”:从一个语义区域提取概念,并将其整合到一个起始于另一个区域的回答中。
当大语言模型不确定如何“架桥”时,阻力最小的路径就是“待在家里”。模型会生成一些流畅的内容,延续问题的框架,而不涉足陌生领域,因为这在统计上是安全的。因此,模型变得“语义懒惰”。
如果这个假设正确,SGI应该与模型内部的不确定性相关——例如注意力模式、对数熵等。低SGI的回答应该显示出“犹豫”的特征。这是一个未来的实验方向。
核心要点
- 第一:简单的几何可以揭示复杂学习系统所错过的结构。研究者花了数月时间试图训练幻觉检测器。最终奏效的,却是两个角度和一个除法。有时,正确的抽象是能最直接地暴露现象的那个,而不是参数最多的那个。
- 第二:预测比观察更重要。发现一个模式很容易。从第一性原理推导出应该存在什么模式,然后去证实它——这才是知道你正在测量真实事物的方法。分层分析虽然不是这项工作中最令人印象深刻的数字,但却是最重要的部分。
- 第三:边界是特性,而非缺陷。SGI在TruthfulQA上完全失效。这个失败比成功更能让人理解这个指标实际测量的是什么。任何声称处处可用的工具,很可能在任何地方都不可靠。
诚实的结论
目前尚不确定语义懒惰是关于语言模型如何失败的一个深刻真理,还是只是恰好适用于当前架构的一个有用近似。机器学习的历史上充满了看似根本实则偶然的洞见。
但就目前而言,我们有了一个“脱离接触”的几何特征签名:一个实用的“幻觉”检测器。它在不同的嵌入模型中表现一致。可以从数学第一性原理进行预测。并且计算成本低廉。
这感觉像是进步。

注:包含完整方法论、统计分析和可复现性细节的科学论文可在 https://arxiv.org/abs/2512.13771 获取。
该工作的BibText引用格式如下:
@misc{marín2025semanticgroundingindexgeometric,
title={Semantic Grounding Index: Geometric Bounds on Context Engagement in RAG Systems},
author={Javier Marín},
year={2025},
eprint={2512.13771},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2512.13771},
}




