

为什么我们需要自动化事实核查系统
相较于传统媒体对文章进行编辑和核实后再发布的严谨流程,社交媒体彻底改变了信息传播的方式。一夜之间,每个人都能自由发声,帖子瞬间被分享至全球,让人们能够接触到来自世界各地的思想和观点。这曾是数字时代的理想愿景。
然而,这种旨在保护言论自由、赋予个人无审查表达意见机会的初衷,也带来了意想不到的弊端。大量信息未经核实便在网络上流传,使得辨别信息真伪的难度达到了前所未有的程度。
一个额外的挑战在于,虚假信息往往不会只出现一次。它们经常在不同平台被重复分享,内容可能在措辞、格式、长度甚至语言上被修改,这无疑增加了检测和核实的难度。当这些变体在不同平台间流传时,它们会因为“似曾相识”而更容易被读者误信。
最初设想的开放、无审查且可靠的信息空间,如今却陷入了一个悖论:正是这种开放性,在赋予人们权力的同时,也为虚假信息的快速传播提供了便利。而这正是事实核查系统发挥关键作用的领域。
事实核查流程(Pipeline)的发展
传统上,事实核查是一个依赖专家(记者、研究人员或事实核查机构)手动进行的过程,他们通过查阅官方文件或专家意见等来源来核实信息。这种方法虽然可靠且深入,但却极其耗时。这种延迟导致虚假信息有更多时间传播、影响公众舆论,并为进一步的操纵创造条件。
自动化技术正是在此背景下应运而生。研究人员开发了事实核查流程,这些流程能够模拟人类事实核查专家的工作方式,但其处理能力可扩展到海量的在线内容。一个典型的事实核查流程遵循结构化的步骤,通常包括以下五个阶段:
-
声明检测 – 识别具有事实含义的陈述。
-
声明优先级排序 – 根据传播速度、潜在危害或公众关注度对声明进行排名,优先处理最具影响力的案例。
-
证据检索 – 收集支持性材料并提供评估所需上下文。
-
真实性预测 – 判断声明是真实的、虚假的,还是介于两者之间。
-
解释生成 – 产生读者易于理解的判断依据。
除了上述五个步骤,许多流程还增加了一个第六步:检索先前已核查的声明(PFCR)。系统不再从头开始重复工作,而是检查一个声明,即使其措辞有所改变,是否已被核实过。如果答案是肯定的,系统会将其链接到相应的事实核查结果及判断。如果未找到匹配项,则流程继续进行证据检索。
这种“捷径”不仅节省了精力,加快了核实速度,在多语言环境下也极具优势,因为它允许以一种语言进行的事实核查支持对另一种语言声明的验证。
该组件有多种称谓,如已验证声明检索、声明匹配或先前已核查声明检索(PFCR)。无论名称如何,其核心思想都是一致的:重复利用已有的知识,以更快、更有效的方式对抗虚假信息。
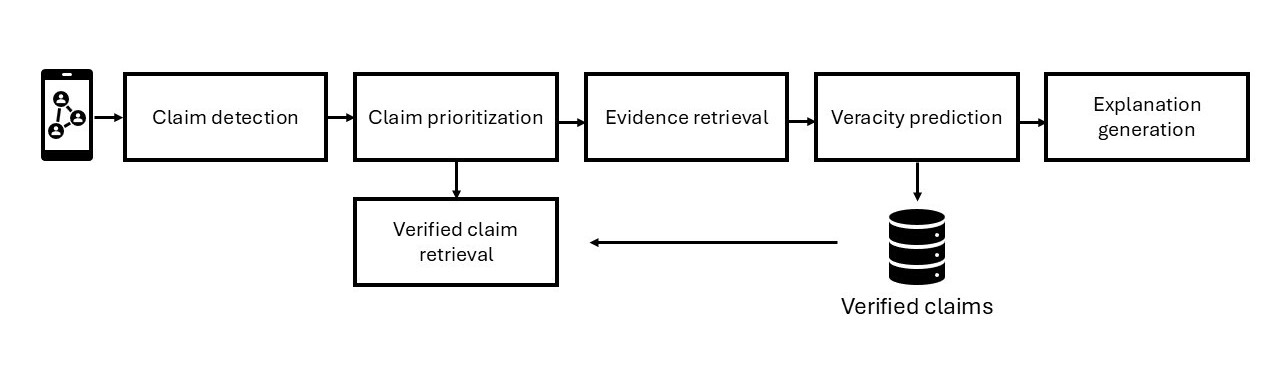
图1:事实核查流程(作者绘制)
PFCR 组件(检索流程)的设计
从本质上讲,先前已核查声明检索(PFCR)是一项信息检索任务:给定社交媒体帖子中的一个声明,目标是在大量已核查(已验证)声明的集合中找到最相关的匹配项。如果存在匹配项,系统可以立即将其链接到原始来源和核查结果,从而无需从零开始进行验证!
大多数现代信息检索系统都采用检索器-重排序器(retriever–reranker)架构。检索器作为第一层过滤器,从语料库中返回一组较大的候选文档(前k个)。随后,重排序器接收这些候选文档,并利用更深层、计算更密集的模型来优化排序。这种两阶段设计在速度(检索器)和准确性(重排序器)之间实现了平衡。
用于检索的模型可分为两大类:
- 词法模型:这类模型速度快、可解释性强,在词汇重叠度高时表现出色。但当思想以不同方式表达(如使用同义词、释义或翻译)时,它们的性能会大打折扣。
- 语义模型:这类模型能够捕捉文本的深层含义而非仅停留在表面词汇,这使其成为PFCR的理想选择。例如,它们能够识别出“地球绕太阳公转”和“我们的行星围绕太阳系中心的恒星旋转”描述的是同一事实,尽管它们的措辞完全不同。
一旦检索到候选文档,重排序阶段会应用更强大的模型(通常是交叉编码器)来精细地重新评分顶部结果,确保最相关的核查结果排名更高。由于重排序器的运行成本较高,它们仅应用于较小的候选池(例如前100个)。
总而言之,检索器-重排序器流程同时提供了覆盖率(通过识别更广泛的可能匹配项)和精确度(通过将最相似的项排在更高位置)。对于PFCR而言,这种平衡至关重要,因为它能够以快速且可扩展的方式检测重复声明,同时保持高准确性,从而使用户能够信任他们所阅读的信息。
构建集成模型(Ensemble)
检索器-重排序器流程本身已经展现出强大的性能。然而,在评估各种模型并进行实验时,一个事实变得清晰:没有哪个单一模型能独善其身。
像BM25这样的词法模型在精确关键词匹配方面表现出色,但一旦声明的措辞发生变化,它们便会力不从心。这时,语义模型就发挥了作用。它们能够轻松处理释义、翻译或跨语言场景,但在一些词汇至关重要的直接匹配中,有时却会遇到挑战。此外,语义模型也并非千篇一律,每个模型都有其独特的优势:有些在英语环境下表现更佳,有些擅长多语言设置,还有些则能捕捉细微的上下文语义。换言之,正如虚假信息会以无数种变体不断变异和重新出现一样,语义检索模型也因其训练方式不同而各有所长。如果虚假信息具有适应性,那么检索系统也必须具备同样的适应能力。
正是基于这种洞察,集成模型(ensemble)的理念应运而生。系统不再寄希望于单一的“最佳”模型,而是将多个模型的预测结果进行整合,使它们能够相互协作、互为补充。与其依赖一个模型,不如让它们像一个团队一样工作。
在深入探讨集成模型的设计之前,有必要简要说明检索器选择的决策过程。
建立基线(词法模型)
BM25是目前最有效且广泛使用的词法检索模型之一,在现代信息检索研究中常被用作基线。在评估基于嵌入的(语义)模型之前,了解BM25的表现如何(无论好坏)是很有意义的。事实证明,它的表现相当不错!
技术细节:BM25是一种基于TF-IDF构建的排序函数。它通过引入饱和函数和文档长度归一化来改进TF-IDF。与简单的词频得分不同,BM25考虑了词语的重复出现,同时防止长文档被不公平地偏向。它还包含一个参数(b)来控制词频和文档长度的权重分配。
语义模型
作为语义(基于嵌入的)模型的起点,参考了HuggingFace的大型文本嵌入基准(MTEB),并在考虑GPU资源限制的情况下,评估了其中的领先模型。
其中脱颖而出的两个模型是E5(intfloat/multilingual-e5-large-instruct)和BGE(BAAI/bge-m3)。这两个模型在检索前100个候选文档时都取得了优异的结果,因此被选中进行进一步的调优和与BM25的集成。
集成模型设计
在确定了检索器之后,接下来的问题是如何将它们结合起来。系统测试了不同的聚合策略,包括多数投票、指数衰减加权和倒数排名融合(RRF)。
倒数排名融合(RRF)表现最佳,因为它不仅仅是简单地平均分数,而是奖励那些在不同排名中始终靠前的文档,无论它们是由哪个模型生成的。通过这种方式,集成模型偏爱多个模型“一致认同”的声明,同时仍然允许每个模型独立贡献其独特优势。
还对第一阶段检索的候选文档数量(通常称为超参数k)进行了实验。这个想法很简单:如果只检索一小部分候选文档,则可能完全错过相关的核查结果。另一方面,如果选择太多,重排序器将不得不处理大量的噪声,这会增加计算成本,而实际上并不能提高准确性。
通过实验发现,随着k的增加,性能最初有所提升,因为集成模型有更多机会找到正确的核查结果。但在某个点之后,增加更多候选文档不再有助于提升性能。重排序器已经能够看到足够多的相关核查结果来做出良好决策,而额外的文档大多是无关的。实践中,这意味着要找到一个“最佳平衡点”,即候选池既要足够大以确保覆盖率,又不能过大以致降低重排序器的效率。
作为最后一步,调整了每个模型的权重。降低BM25的影响力,同时赋予语义检索器更大的权重,显著提升了整体性能。换句话说,BM25虽然有用,但主要工作是由E5和BGE完成的。
简要回顾PFCR组件:该流程由检索和重排序组成,检索阶段可以使用词法或语义模型,而重排序阶段则使用语义模型。此外,通过将多个模型集成在一起,可以显著提升检索/重排序的性能。那么,这个集成模型应该如何融入整个流程呢?
集成模型如何融入整体流程?
集成模型并非仅限于流程的某一部分。它被应用于检索和重排序两个阶段。
-
检索阶段 → 将BM25、E5和BGE模型生成的候选列表进行了融合。通过这种方式,系统不再依赖单一模型对相关性的“看法”,而是将它们的视角汇集起来,形成一个更强大的初始候选集。
-
重排序阶段 → 随后,结合了多个重排序器(同样是根据MTEB和GPU资源限制选择)的排名结果。由于每个重排序器都能捕捉到相似性中略微不同的细微差别,因此将它们融合有助于以更高的准确性精炼事实核查的最终排序。
在检索阶段,集成模型提供了更广泛的候选池,确保更少的相关声明被遗漏(从而提高了召回率)。而在重排序阶段,它则缩小了关注范围,将最相关的核查结果推至顶部(从而提高了精确率)。
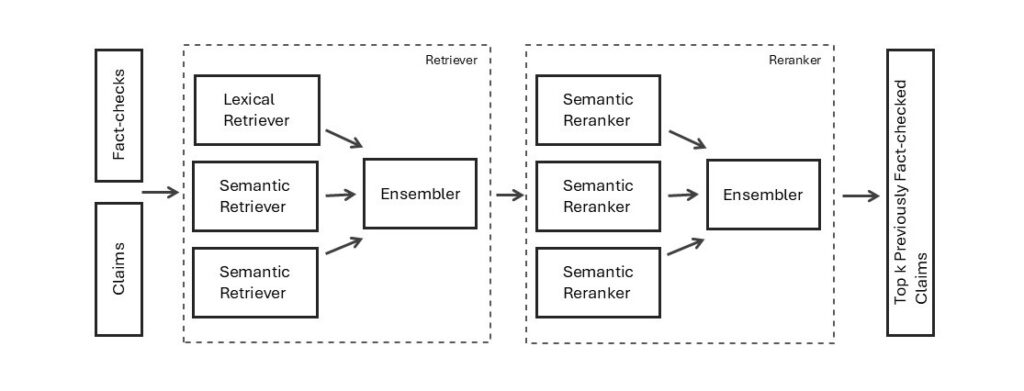
图2:检索器-重排序器集成流程(作者绘制)
总结(TL;DR)
长话短说:设想中开放信息共享的数字乌托邦,若没有核查机制将无法运作,甚至可能适得其反,成为虚假信息传播的渠道。
正是这种需求推动了自动化事实核查流程的发展,使人类更接近最初的承诺。这些系统能够帮助我们快速、大规模地验证信息,因此当虚假声明以新形式出现时,它们能够被及时发现和处理,从而有助于维护数字世界的准确性和信任。
核心启示很简单:多样性是关键。正如虚假信息以多种形式传播一样,一个有弹性的事实核查系统也受益于多种视角的协同工作。通过使用集成模型,事实核查流程变得更加健壮、更具适应性,并最终能够打造一个值得信赖的数字空间。
致好奇的读者
如果您对该流程背后的检索和集成策略有更深入的技术兴趣,可以查阅此处提供的完整论文链接。该论文详细介绍了系统中的模型选择、实验过程以及详细的评估指标。
参考文献
Scott A. Hale, Adriano Belisario, Ahmed Mostafa, and Chico Camargo. 2024. Analyzing Misinformation Claims During the 2022 Brazilian General Election on WhatsApp, Twitter, and Kwai. ArXiv:2401.02395.
Rrubaa Panchendrarajan and Arkaitz Zubiaga. 2024. Claim detection for automated fact-checking: A survey on monolingual, multilingual and cross-lingual research. Natural Language Processing Journal, 7:100066.
Matúš Pikuliak, Ivan Srba, Robert Moro, Timo Hromadka, Timotej Smolen, Martin Melišek, Ivan ˇ Vykopal, Jakub Simko, Juraj Podroužek, and Maria Bielikova. 2023. Multilingual Previously FactChecked Claim Retrieval. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 16477–16500, Singapore. Association for Computational Linguistics.
Preslav Nakov, David Corney, Maram Hasanain, Firoj Alam, Tamer Elsayed, Alberto Barrón-Cedeño, Paolo Papotti, Shaden Shaar, and Giovanni Da San Martino. 2021. Automated Fact-Checking for Assisting Human Fact-Checkers. ArXiv:2103.07769.
Oana Balalau, Pablo Bertaud-Velten, Younes El Fraihi, Garima Gaur, Oana Goga, Samuel Guimaraes, Ioana Manolescu, and Brahim Saadi. 2024. FactCheckBureau: Build Your Own Fact-Check Analysis Pipeline. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, CIKM ’24, pages 5185–5189, New York, NY, USA. Association for Computing Machinery
Alberto Barrón-Cedeño, Tamer Elsayed, Preslav Nakov, Giovanni Da San Martino, Maram Hasanain, Reem Suwaileh, Fatima Haouari, Nikolay Babulkov, Bayan Hamdan, Alex Nikolov, Shaden Shaar, and Zien Sheikh Ali. 2020. Overview of CheckThat! 2020: Automatic Identification and Verification of Claims in Social Media. In Experimental IR Meets Multilinguality, Multimodality, and Interaction, pages 215–236, Cham. Springer International Publishing.
Ashkan Kazemi, Kiran Garimella, Devin Gaffney, and Scott Hale. 2021a. Claim Matching Beyond English to Scale Global Fact-Checking. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4504–4517, Online. Association for Computational Linguistics.
Shaden Shaar, Nikolay Babulkov, Giovanni Da San Martino, and Preslav Nakov. 2020. That is a Known Lie: Detecting Previously Fact-Checked Claims. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3607– 3618, Online. Association for Computational Linguistics.
Alberto Barrón-Cedeño, Tamer Elsayed, Preslav Nakov, Giovanni Da San Martino, Maram Hasanain, Reem Suwaileh, Fatima Haouari, Nikolay Babulkov, Bayan Hamdan, Alex Nikolov, Shaden Shaar, and Zien Sheikh Ali. 2020. Overview of checkthat! 2020: Automatic identification and verification of claims in social media. In Experimental IR Meets Multilinguality, Multimodality, and Interaction: 11th International Conference of the CLEF Association, CLEF 2020, Thessaloniki, Greece, September 22–25, 2020, Proceedings, page 215–236, Berlin, Heidelberg. Springer-Verlag.
Gordon V. Cormack, Charles L A Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’09, page 758–759, New York, NY, USA. Association for Computing Machinery





