


英伟达、甲骨文、谷歌、戴尔以及其他 13 家公司公布了其计算机训练当前主流神经网络所需的时间。这些结果中包括英伟达下一代 GPU B200 和谷歌即将推出的加速器 Trillium 的首次亮相。B200 在某些测试中比当前主力芯片 H100 的性能提升了一倍。而 **Trillium** 则比谷歌在 2023 年测试的芯片性能提升了近四倍。
这些名为 MLPerf v4.1 的基准测试包含六项任务:推荐系统、大型语言模型 (LLM) GPT-3 和 BERT-large 的预训练、Llama 2 70B 大型语言模型的微调、目标检测、图节点分类和图像生成。
训练 GPT-3 是一项极其庞大的任务,仅为了基准测试而进行完整的训练是不切实际的。因此,测试的目标是训练模型到专家认定的能够达到目标的程度,即使继续训练下去也能达到预期效果。对于 Llama 2 70B,目标不是从头开始训练 LLM,而是对已经训练好的模型进行微调,使其专门用于特定领域,在本例中是政府文件。图节点分类是一种机器学习类型,用于欺诈检测和药物发现。
随着人工智能领域重点的转变,主要转向生成式人工智能,测试集也随之改变。MLPerf 的最新版本标志着自基准测试工作开始以来,测试内容的彻底改变。“目前,所有原始基准测试都已淘汰,”MLCommons 基准测试负责人 David Kanter 说。在上一轮测试中,一些基准测试的执行时间仅需几秒钟。
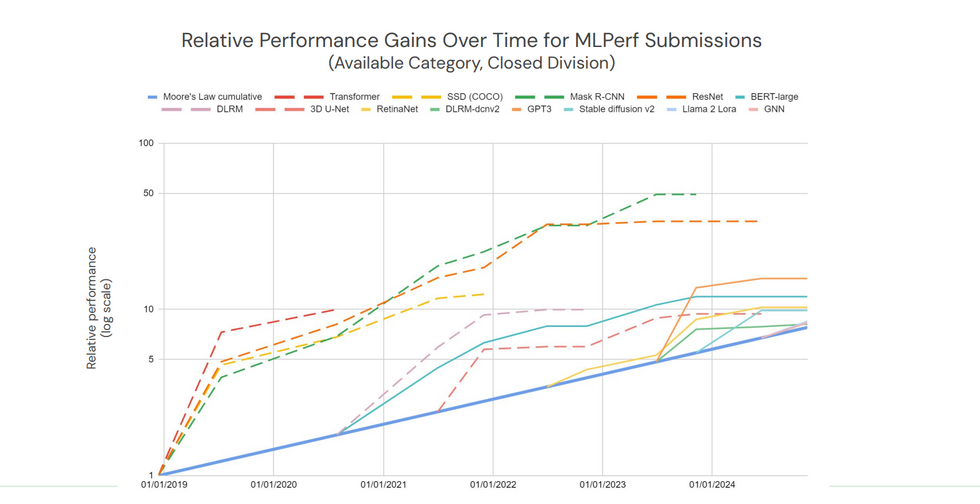
各种基准测试中最佳机器学习系统的性能超过了摩尔定律预期(蓝色线)。实线代表当前基准测试。虚线代表已淘汰的基准测试,因为它们不再具有工业意义。MLCommons
根据 MLPerf 的计算,新基准测试套件上的 AI 训练速度大约是摩尔定律预期速度的两倍。随着时间的推移,测试结果的增长速度比 MLPerf 刚开始时要慢得多。Kanter 将此归因于公司已经找到了在大型系统上执行基准测试的方法。随着时间的推移,英伟达、谷歌和其他公司开发了软件和网络技术,实现了近乎线性的扩展——处理器数量翻倍,训练时间大约减半。
英伟达 Blackwell 首次训练结果
本轮测试是英伟达下一代 GPU 架构 Blackwell 的首次训练测试。在 GPT-3 训练和 LLM 微调方面,Blackwell (B200) 的性能大约是 H100 的两倍。在推荐系统和图像生成方面,性能提升幅度略小,但仍然相当可观,分别为 64% 和 62%。
Blackwell 架构,体现在英伟达 B200 GPU 中,延续了使用越来越少的精确数字来加速 AI 的趋势。对于 ChatGPT、Llama2 和 Stable Diffusion 等 Transformer 神经网络的某些部分,英伟达 H100 和 H200 使用 8 位浮点数。B200 将其降低到仅 4 位。
谷歌推出第六代硬件
谷歌展示了其第六代 TPU(名为 Trillium)的首次结果,这款 TPU 仅在上个月发布。此外,谷歌还展示了其第五代变体 Cloud TPU v5p 的第二轮结果。在 2023 年的版本中,这家搜索巨头推出了第五代 TPU 的另一个变体 v5e,该变体更注重效率而不是性能。与 v5e 相比,Trillium 在 GPT-3 训练任务上的性能提升了 3.8 倍。
但与所有人的主要竞争对手英伟达相比,情况并不那么乐观。由 6144 个 TPU v5p 组成的系统在 11.77 分钟内完成了 GPT-3 训练检查点,远远落后于由 11616 个英伟达 H100 组成的系统,后者在约 3.44 分钟内完成了任务。该顶级 TPU 系统只比规模只有其一半的 H100 计算机快了大约 25 秒。
戴尔科技公司使用约 75 美分的电费对 Llama 2 70B 大型语言模型进行了微调。
在 v5p 和 Trillium 之间最直接的对比中,每个系统都由 2048 个 TPU 组成,即将推出的 Trillium 将 GPT-3 训练时间缩短了整整 2 分钟,比 v5p 的 29.6 分钟提高了近 8%。Trillium 和 v5p 之间的另一个区别是,Trillium 与 AMD Epyc CPU 配合使用,而 v5p 则与英特尔 Xeon 配合使用。
谷歌还使用 Cloud TPU v5p 训练了图像生成器 Stable Diffusion。Stable Diffusion 的参数量为 26 亿,规模较小,MLPerf 参赛者被要求将其训练到收敛,而不是像 GPT-3 那样只训练到检查点。由 1024 个 TPU 组成的系统排名第二,在 2 分钟 26 秒内完成了任务,比由相同数量的英伟达 H100 组成的系统慢了大约 1 分钟。
https://public.flourish.studio/visualisation/20251…” target=”_blank”>https://public.flourish.studio/visualisation/20251…” width=”100%” alt=”chart visualization” />
训练能力仍然不透明
训练神经网络的高昂能源成本一直是人们关注的焦点。MLPerf 只是开始对此进行衡量。戴尔科技公司是能源类别中唯一的参赛者,其系统包含 8 台服务器,其中包含 64 个英伟达 H100 GPU 和 16 个英特尔至强铂金 CPU。唯一的测量指标是在 LLM 微调任务(Llama2 70B)中进行的。该系统在 5 分钟的运行过程中消耗了 16.4 兆焦耳,平均功率为 5.4 千瓦。这意味着在美国平均电价下,大约需要 75 美分的电费。
虽然这个结果本身并不能说明太多问题,但它可能为类似系统的功耗提供了一个参考范围。例如,甲骨文报告了使用相同数量和类型的 CPU 和 GPU 实现了相似的性能结果——4 分钟 45 秒。




