一次 Text-to-SQL 系统的深度优化实践
一、痛点:维护成本高、准确率低
1.1 数据化的痛点
在 ChatBI 智能问答系统上线一段时间后,运营阶段遇到了三个费时费力的核心问题:
问题1:海量别名维护成本极高
- 维度值数量:系统中,汽车行业集团名称 70+ 个,车型名称 200+ 个,品牌名称 50+ 个
- 别名数量:每个实体平均 3-5 个别名,总计需要维护1000+ 个别名映射
- 维护方式:高频查询内容硬编码在 LLM 的 Prompt 中,但低频查询不可避免地会出错
- Prompt 长度: 大模型生成 SQL 提示词超过5000 字,消耗大量 Token
- 新增成本:每增加一个车型,需要修改 Prompt 并重新测试,耗时30 分钟以上
问题2:用户表达多样化导致准确率低
- 初始准确率:仅80%
- 典型失败案例:
- 用户输入 “byd” → 系统无法识别(未在 Prompt 中穷举)
- 用户输入 “传祺向往 S7” → 系统只认识 “S7″(别名组合未覆盖)
- 用户输入 “迪子” → 系统不知道是 “比亚迪汽车”(俚语别名未收录)
问题3:扩展性差
- 新车型上市:需要修改代码或 Prompt
- 新别名出现:需要重新部署
- 跨表查询:同一别名在不同表中可能对应不同标准名
1.2 量化的业务影响
- 用户体验:每天约15%-20%的查询失败影响业务感知
- 运维成本:每周需要2-3 小时维护别名映射
二、效果:准确率提升至 90%以上,维护成本降低 90%
项目组大概用了 1 个月的时间,参考了行业诸多 N2SQL 类产品的解题思路。
在 Dify 系统上,通过巧妙的别名配置知识库优化+代码提取,实现了查询准确性提升、维护难度降低以及响应时间缩短等多项指标成果。

2.1 核心指标对比
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 准确率 | 80% | 90%+ | +10% |
| Prompt 长度 | ~5000 字 | ~2500 字 | -50% |
| Token 消耗 | 高 | 中 | -30% |
| 新增车型耗时 | 30 分钟 | <1 分钟 | -90% |
| 维护成本 | 2-3 小时/周 | <30 分钟/周 | -80% |
| 响应时间 | ~2000ms | ~1000ms | -1000ms |
2.2 实际测试结果
测试规模:100+ 测试用例
测试结果:
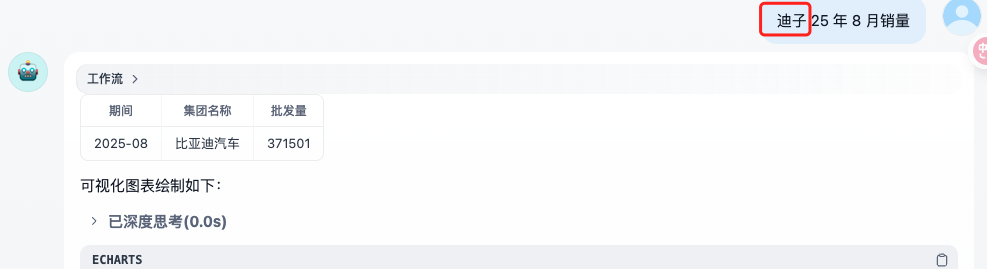
- ✅ “迪子2025 年 8月 销量” → 正确识别为 “比亚迪汽车25年8月的销量”
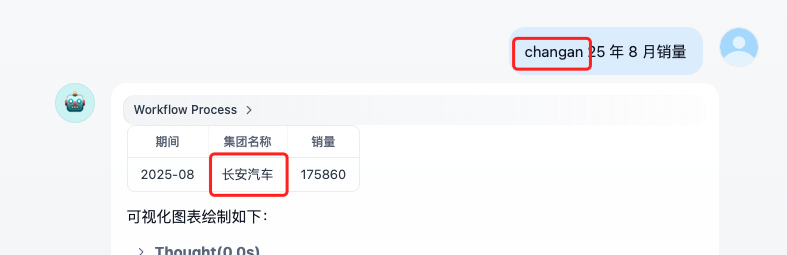
- ✅ “changan 25年 8 月销量” → 正确识别为 “长安汽车 25 年 8 月的产量”
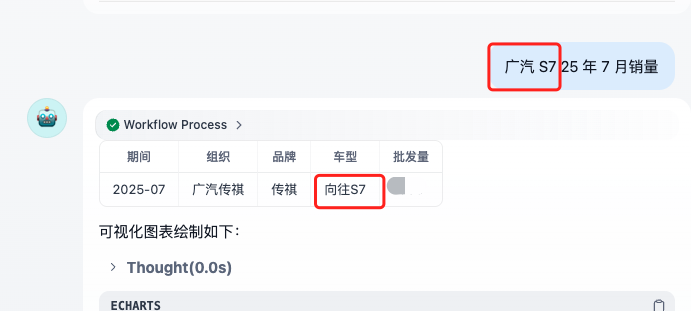
- ✅ “广汽 S7 25 年 7 月销量” → 正确识别为 “广汽集团向往 S7 的批发量”
三、解决方案思路总览
3.1 核心理念:三层混合架构
方案采用了“不穷举、分层处理、智能匹配”的设计理念:
**用户问题** ↓【第一层】Prompt 约定(10-20 个核心高频词) ↓ 100% 准确,零延迟【第二层】RAG 知识库检索(中低频+长尾情况解决) ↓ 语义理解,自动召回 ↓ 无需穷举,自动处理标准化问题 → SQL 生成3.2 技术架构
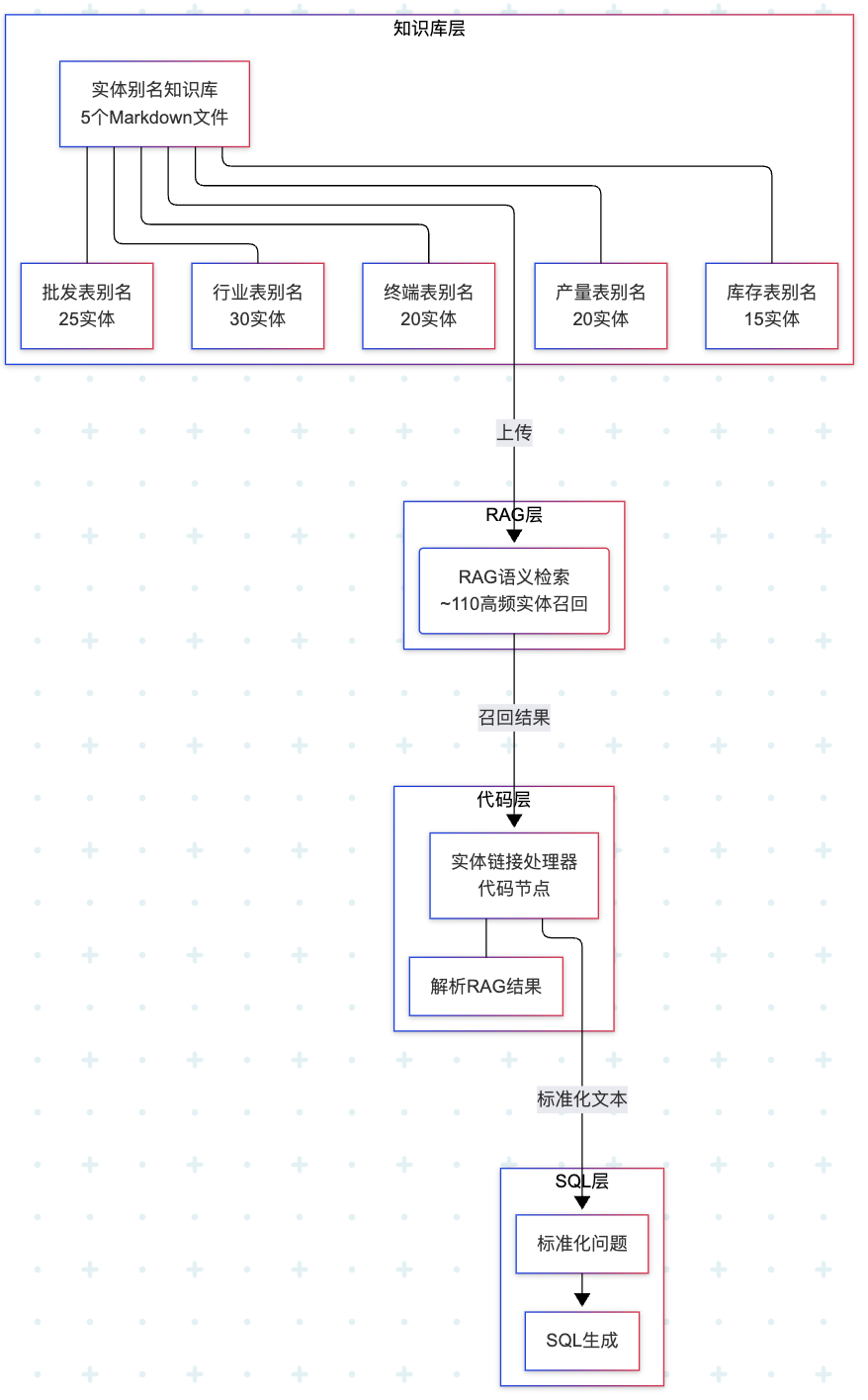
四、分步解决方案
步骤 1:构建实体别名知识库
1.1 按表分文件策略
为每个数据表创建独立的别名知识库文件:
为什么按表分文件?
- ✅ 提高 RAG 检索精度
- ✅ 减少噪音干扰
- ✅ 易于维护和扩展
文件结构:
### 集团:比亚迪汽车**标准查询名**:比亚迪汽车 **常见别名**:比亚迪、BYD、byd、迪子 **所属表**:行业表 **字段名**:group_name
1.2 知识库配置
在 Dify 中创建知识库的配置如下:
名称:实体别名库_全部文件:5 个 md 文件(行业表、批发表、终端表、产量表、库存表)配置: 检索模式:混合检索 权重设置:语义 0.7,关键词 0.3 Top K:3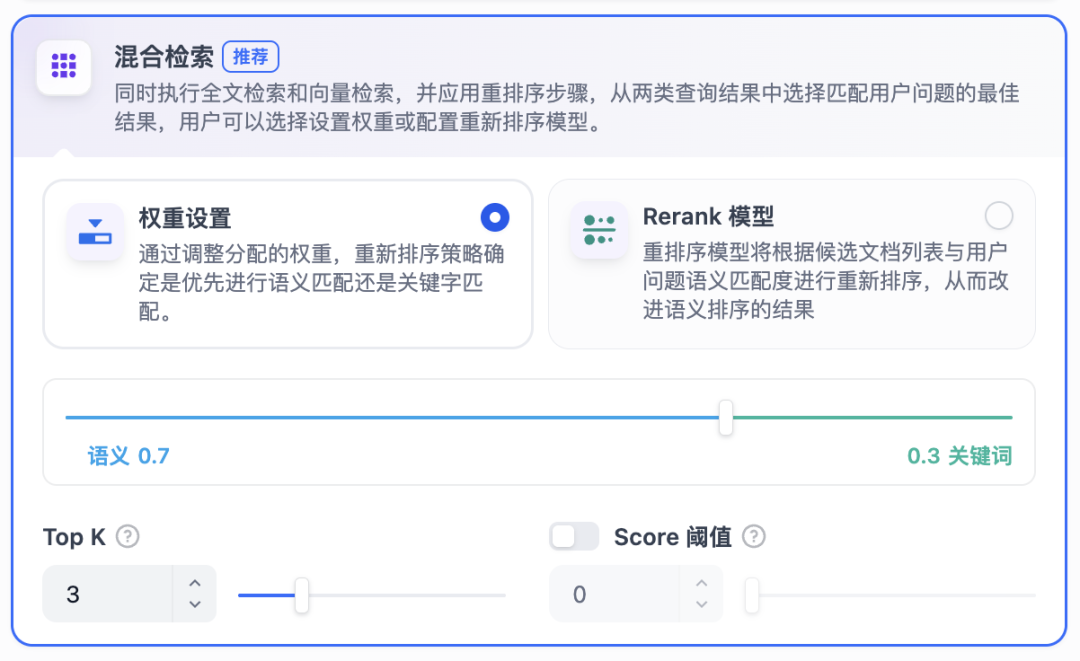
关键配置说明:
- Top K = 3:确保召回的候选实体精度
- 混合检索:兼顾语义和关键词
步骤 2:构建实体链接处理器(30 分钟)

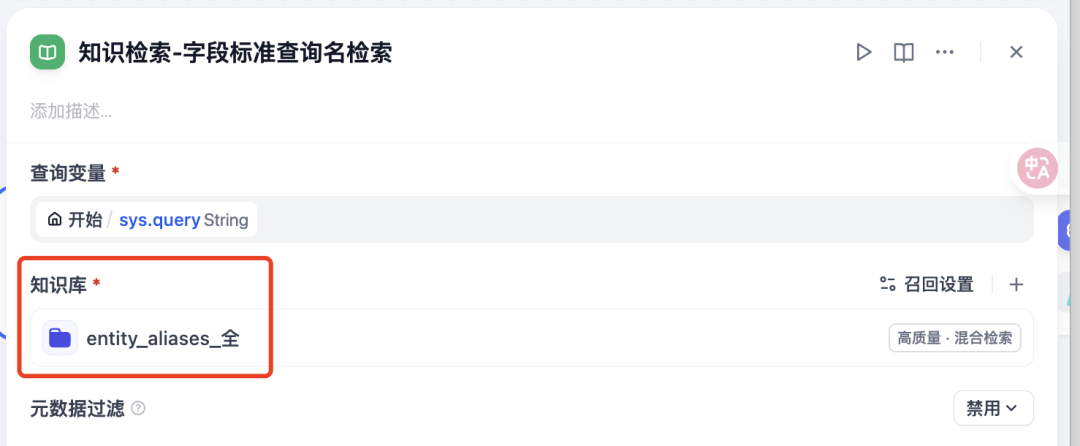
2.1 知识检索节点设计
在 Dify 工作流中添加知识检索节点,如图所示:
2.2 RAG 实体解析(代码节点)
输入变量 arg1 选择上一个节点输出的检索结果。
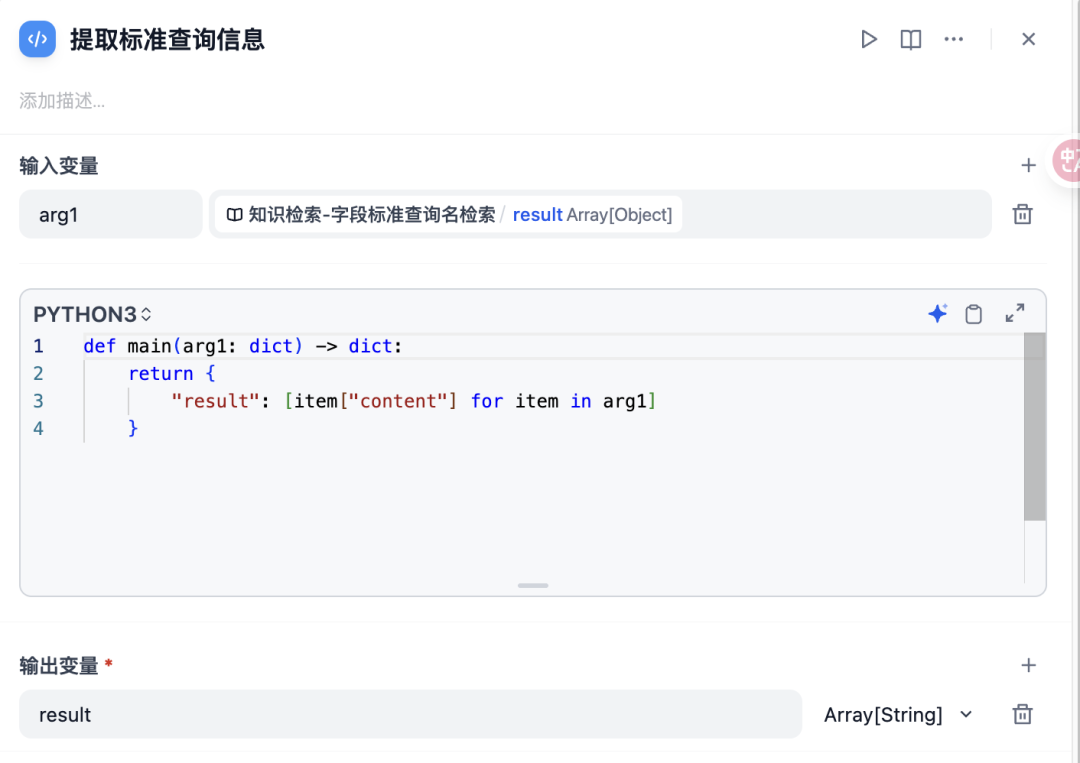
代码区域输入如下代码:
def main(arg1: dict) -> dict: return { "result": [item["content"] for item in arg1] }输出变量为 result,变量类型选择 Array [String]。
步骤 3:修改 AI 生成 SQL 节点(15 分钟)
3.1 简化 Prompt
删除内容(约 2500 字):
# 二、组织和别名- **一汽集团**(又名 一汽、一汽汽车)- **长安汽车**(又名 长安)- **东风**(又名 东风集团)- **长城**(又名 长城汽车)- **悦达**(又名 悦达集团)- **零跑汽车**(又名 零跑)- **福特**(又名 福特汽车)- **小鹏汽车**(又名 小鹏)- **小米汽车**(又名 小米)- **蔚来汽车**(又名 蔚来)- **比亚迪**(又名 比亚迪汽车)- **上汽**(又名 上汽集团)- **吉利**(又名 吉利汽车)(删除所有硬编码的别名定义)保留内容:
# 黄金准则 0-5(核心 SQL 生成规则)# 一、核心指标说明# 三、报表和字段说明(DDL)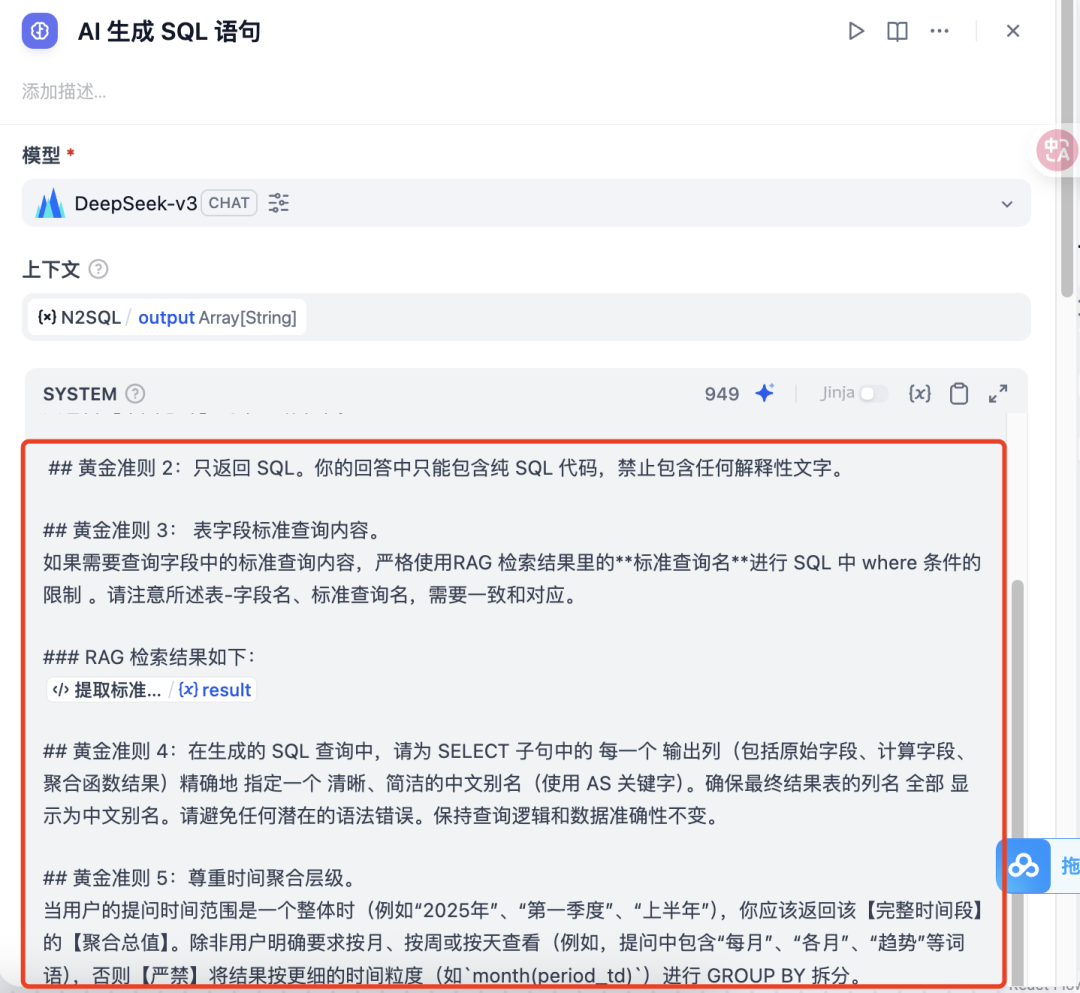
3.2 修改知识检索
修改为:
{{#提取标准查询信息.result#}}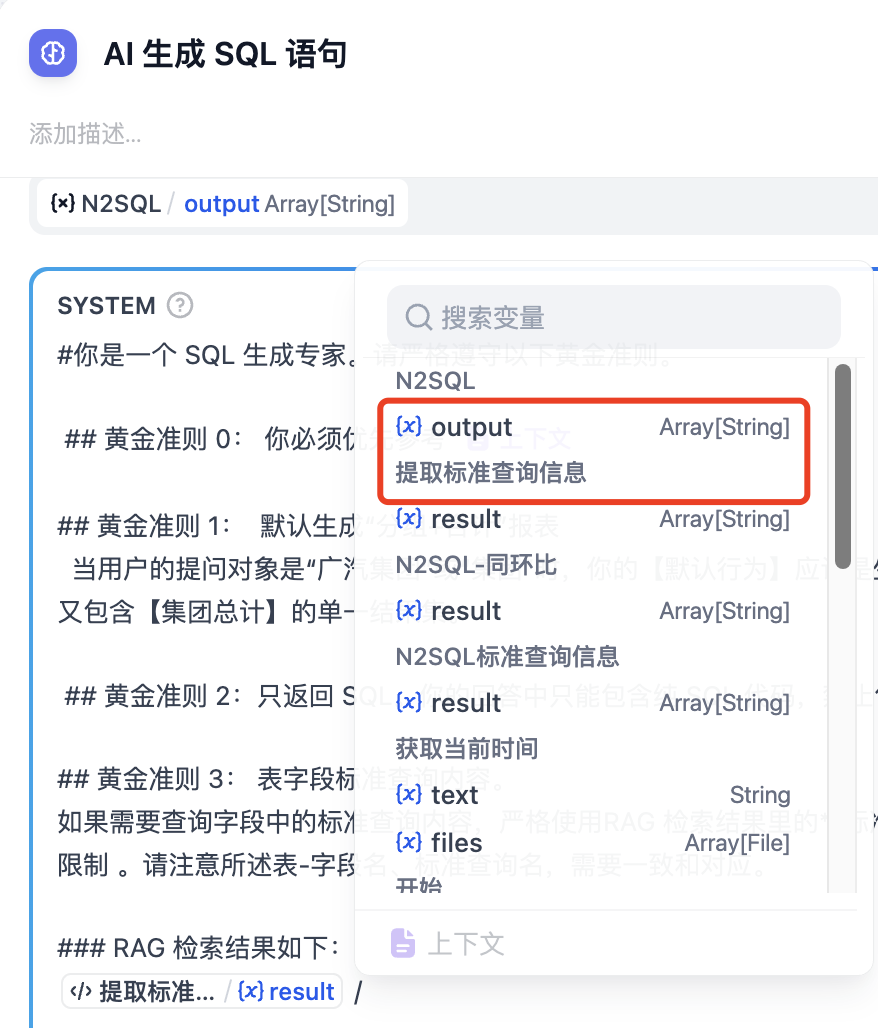
效果:
- Prompt 长度从 ~5000 字减少到 ~2500 字
- Token 消耗减少 30%
- LLM 理解更清晰,准确率提升
五、意义和价值
技术价值
- 1. 架构创新
- 三层混合架构:代码字典 + RAG + 智能匹配
- 无需穷举所有别名,维护成本降低 90%
- 2. 可扩展性
- 新增实体只需添加 Markdown 段落
- 支持批量导入和更新
- 易于跨团队协作
- 3. 可复用性
- 方案可应用于其他 Text-to-SQL 场景
- 代码节点可复用于其他 Dify 工作流
- 知识库管理模式可推广
六、后续优化方向
6.1 短期优化(1-3 个月)
1. 自动化补充
- 目标:自动发现和补充新别名
- 方案:分析未匹配词,自动生成补充建议
- 预期:维护成本再降低 50%
2. 跨表关联优化
- 智能识别跨表查询
- 自动选择最优表组合
- 提升复杂查询性能
3. 多模态支持
- 支持语音输入
- 支持图表识别
- 支持自然语言 + 图表混合查询
4. 智能推荐
- 基于历史查询推荐相关问题
- 智能补全用户输入
- 提供查询优化建议
5. 知识图谱集成
- 构建实体关系图谱
- 支持更复杂的语义理解
- 提升准确率至 99%+
七、总结
核心经验
- 不要试图穷举 – 只维护高频实体,依赖 RAG 处理长尾
- 分层处理 – 代码字典 + RAG + 智能匹配,各司其职
- 持续优化 – 监控数据,及时补充知识库
- 量化评估 – 用数据说话,持续改进
附录:技术栈
- 平台:Dify
- LLM:DeepSeek-v3
- 向量模型:BAAI/bge-m3
- Rerank 模型:netease-youdao/bce-reranker-base_v1
- 编程语言:Python 3
- 知识库格式:Markdown