

当有人声称他们发明了一种革命性的人工智能架构时,人们会发现,选择性放大与归一化这两种数学模式在梯度下降、生物进化和化学反应中独立地涌现出来。这表明,我们并非在Transformer架构中“发明”了注意力机制,而是在能源约束下,重新发现了任何系统处理信息所遵循的基本优化原则。将注意力理解为信号放大而非简单选择,不仅能为未来的架构改进提供具体方向,也能解释现有方法为何奏效。只需八分钟阅读此文,便能获得一种心智模型,有望指导未来十年更优秀的系统设计。
2017年,Vaswani及其同事发表了题为《Attention Is All You Need》的论文 [1],当时他们认为提出了一种革命性的方案。他们的Transformer架构彻底摒弃了循环网络,转而依赖注意力机制来同步处理整个文本序列。其数学核心简洁明了:计算位置间的兼容性得分,将其转化为权重,并利用这些权重对信息进行选择性组合。
然而,这种模式似乎在任何面临资源约束和复杂性的信息处理系统中独立涌现。这并非因为存在某种普适的注意力法则,而是因为某些数学结构似乎代表了对基本优化问题的收敛性解决方案。
这或许是少数情况之一,生物学、化学和人工智能在相似的计算策略上取得了殊途同归——并非通过共享的机制,而是通过共享的数学约束。
五亿年的进化实验
注意力类机制在生物学中的证据 Remarkably 深入。视顶盖/上丘系统通过竞争性抑制实现空间注意力,在脊椎动物中表现出非凡的进化保守性 [2]。从鱼类到人类,这种神经架构在超过五亿年的进化历程中保持了结构和功能的连贯性。
然而,更令人着迷的或许是趋同进化。
独立的生物谱系多次演化出类似注意力的选择性处理机制:昆虫的复眼系统 [3]、头足类动物的晶状体眼 [4]、鸟类的分层视觉处理 [5],以及哺乳动物的皮层注意力网络 [2]。尽管神经架构和进化历史截然不同,这些系统却在选择性信息处理方面趋同于相似的解决方案。
这引出了一个引人深思的问题:这是否是基本计算约束的证据,这些约束决定了复杂系统在资源有限的情况下必须如何处理信息?
即使是简单的生物体也表明这种模式具有显著的普适性。秀丽隐杆线虫(C. elegans)仅有302个神经元,却在觅食和避险中表现出复杂的注意力类行为 [6]。植物也展现出类似注意力的选择性资源分配,将生长响应导向相关的环境刺激,同时忽略其他刺激 [7]。
进化的保守性令人惊叹,但在进行直接等价时应保持谨慎。生物注意力涉及特定的神经回路,这些回路由与产生AI架构的优化景观截然不同的进化压力所塑造。
将注意力理解为放大:机制重构
最近的理论工作从根本上挑战了我们对注意力机制的理解。哲学家Peter Fazekas和Bence Nanay证明,传统的“过滤器”和“聚光灯”隐喻从根本上误解了注意力机制的实际作用 [8]。
他们认为,注意力并非选择输入,而是以一种非刺激驱动的方式放大突触前信号,并与内置的归一化机制相互作用,从而产生选择的表象。他们所识别的数学结构如下:
- 放大:增强某些输入信号的强度。
- 归一化:内置机制(如除法归一化)处理这些被放大的信号。
- 表观选择:两者的结合产生了看似选择性过滤的效果。
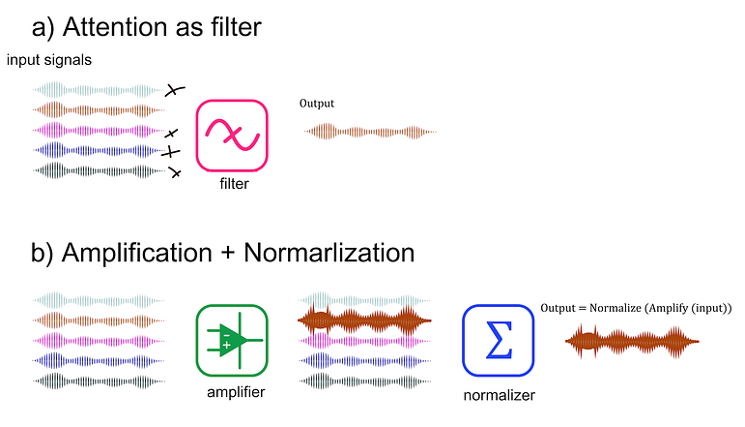
图1:注意力机制并非过滤输入,而是放大特定信号,再通过归一化产生表观选择性。这就像带有自动增益控制的调音台,结果看似是选择性的,但其内在机制是放大。
这一框架解释了神经科学中看似矛盾的发现。例如,增加的放电率、感受野缩小和周边抑制等效应,都源于相同的底层机制——放大与独立于注意力运行的归一化计算之间的相互作用。
Fazekas和Nanay主要关注生物神经系统。这种放大框架是否能扩展到其他领域仍然是开放性问题,但数学上的相似之处极具启发性。
化学计算机与分子放大
或许最令人惊讶的证据来自化学系统。Baltussen及其同事证明,福尔摩斯反应(一种涉及甲醛、二羟基丙酮和金属催化剂的自催化反应网络)能够执行复杂的计算 [9]。
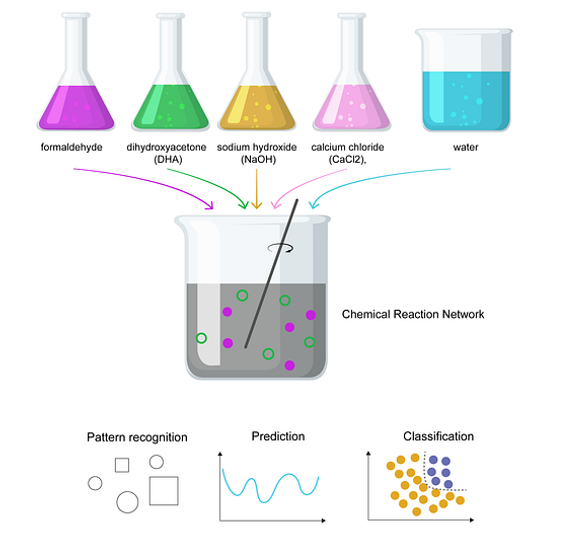
图2:化学计算机的运行:在一个搅拌反应器中混合五种简单化学物质,便会发生令人惊叹的现象——这种化学混合物能够识别模式、预测未来变化并对信息进行分类。无需编程,无需训练,无需硅芯片,仅仅是分子在进行数学运算。这种福尔摩斯反应网络利用了与ChatGPT注意力机制相同的选择性放大原理来处理信息,但它是通过纯粹的化学过程自然演化而来。
该系统在多达10⁶种不同分子物种中表现出选择性放大,在非线性分类任务上实现了超过95%的准确率。不同的分子物种对输入模式做出差异响应,通过选择性放大产生了看似化学注意力的效果。值得注意的是,该系统运行时间尺度(500毫秒到60分钟)与生物和人工注意力机制的时间尺度有所重叠。
然而,该化学系统缺乏生物注意力所特有的分层控制机制和学习动态。但其数学结构——选择性放大产生表观选择性——却惊人地相似。可编程自催化网络提供了额外证据。像Nd³⁺这样的金属离子能够创建双相控制机制,根据浓度既能加速也能抑制反应 [10]。这通过纯粹的化学过程生成了可控的选择性放大,实现了布尔逻辑函数和多项式映射。
信息论约束与普适优化
这些不同领域间的趋同可能反映了更深层次的数学必然性。信息瓶颈理论提供了一个正式的框架:任何处理能力有限的系统都必须解决一个优化问题,即在保留与任务相关细节的同时,最小化信息冗余 [11]。
Jan Karbowski关于信息热力学的研究揭示了信息处理的普适能量约束 [12]。计算的基本热力学界限,为所有能够进行计算的基质上的高效选择性处理机制创造了选择压力:
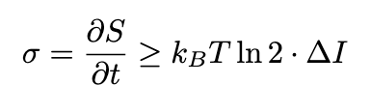
信息处理需要消耗能量,因此高效的注意力机制在生存/性能上具有优势,其中 σ 代表熵 (S) 产生率,ΔI 代表信息处理能力。
无论任何系统——无论是大脑、计算机,甚至化学反应——处理信息时,都必须以废热的形式耗散能量。处理的信息越多,浪费的能量就越多。由于注意力机制处理信息(决定关注什么),它们同样受到这种能量税的制约。
这为高效架构创造了普适性压力——无论进化设计的是大脑、化学反应组织的是分子,还是梯度下降训练的是Transformer模型。
在临界状态(秩序与混沌的边缘)运行的神经网络,在保持稳定性的同时,最大化了信息处理能力 [13]。经验测量表明,人类有意识的注意力恰好发生在这些临界转变点 [14]。Transformer网络在训练过程中也表现出类似的相变,在信息处理达到最优的临界点附近组织注意力权重 [15]。
这表明,只要系统面临处理能力和能源效率在资源约束下的基本权衡,类似注意力的机制就可能出现。
数学趋同,而非机制普适
现有证据指向一个初步结论。我们可能并非发现了普适的机制,而是在见证对相似优化问题的收敛性数学解:
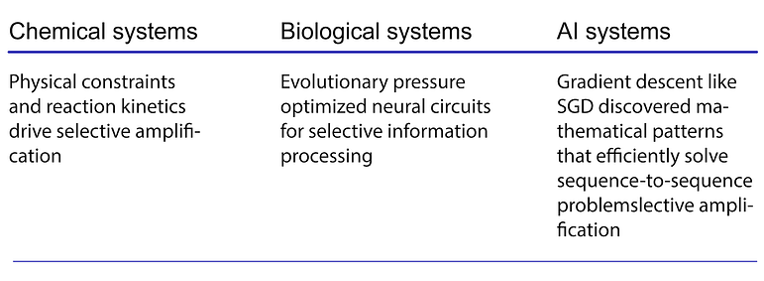
选择性放大与归一化相结合的数学结构在这些不同领域中均有体现,但其潜在机制和约束条件却大相径庭。
对于Transformer架构而言,这种重新理解提供了具体的见解:
- Q·K 计算实现了放大。
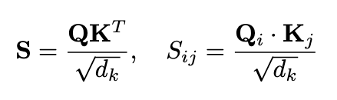
点积 Q·K^T 计算查询(Query)与键(Key)表示之间的语义兼容性,充当学习到的放大函数;高兼容性得分会放大信号通路。缩放因子 √d_k 可防止在高维空间中出现饱和,从而维持梯度流。
- Softmax 归一化产生“赢者通吃”动态。
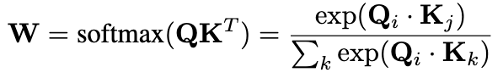
Softmax 通过除法重归一化实现竞争性归一化。指数项放大差异(产生“赢者通吃”动态),而和归一化确保 Σw_ij = 1。在数学上,此函数等同于除法归一化。
- 加权 V 组合产生表观选择性。

在这种组合中,没有明确的选择操作符,它本质上是值向量的线性组合。表观选择性源于 Softmax 归一化所引起的稀疏模式。高注意力权重能够在没有明确门控机制的情况下创建有效的门控。
softmax(放大)的组合在值空间上引入了一种“赢者通吃”的动态。

对AI发展的启示
将注意力理解为放大与归一化的结合而非简单选择,为AI架构设计提供了几点实用见解:
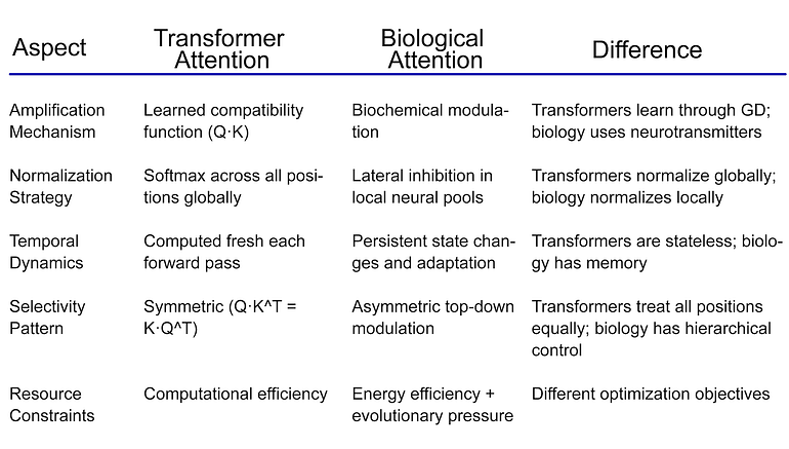
- 分离放大与归一化:当前的Transformer架构将这些机制混为一谈。探索能够解耦它们的架构,允许采用超越Softmax的更灵活的归一化策略,可能会带来更好的效果 [16]。
- 非内容驱动的放大:生物注意力包含“非刺激驱动”的放大。当前Transformer的注意力纯粹基于内容(Q·K兼容性)。研究学习到的位置偏差、任务特定的放大模式或元学习的放大策略可能有所助益。
- 局部归一化池:生物学利用“周围神经元池”进行归一化,而非全局归一化。这提示可以探索局部注意力邻域、跨层级归一化或动态归一化池选择。
- 临界动力学:注意力机制在临界点附近运行的证据表明,有效的注意力机制应表现出特定的统计特征——幂律分布、雪崩动力学和临界涨落 [17]。
开放性问题与未来方向
几个基本问题仍然存在:
- 数学上的相似性到底有多深?我们看到的是真正的计算等价,还是表面的相似性?
- 化学储层计算能给我们带来关于最小注意力架构的哪些启示?如果简单的化学网络能够实现类似注意力的计算,这对于AI注意力机制的复杂性要求意味着什么?
- 信息论约束是否能预测注意力在扩展AI系统中的演化?随着模型规模的扩大和面临更复杂的环境,注意力机制是否会自然演化出这些普适的优化原则?
- 如何将生物学关于分层控制和适应的见解融入AI架构?静态的Transformer注意力与动态的生物注意力之间仍然存在巨大鸿沟。
结论
注意力机制的故事,似乎更多关乎“再发现”,而非“发明”。无论是在福尔摩斯反应的化学网络中,上丘的神经回路里,还是在Transformer架构的学习权重中,我们都看到了一个共同的数学主题:选择性放大与归一化相结合,以产生表观选择性。
这并未减损Transformer架构的成就——如果说有什么影响,那便是它揭示了一个超越特定实现方式的基础计算洞察。在资源有限的条件下,控制高效信息处理的数学约束似乎正在推动不同的系统走向相似的解决方案。
随着AI系统不断扩展,理解这些更深层次的数学原理,可能比直接模仿生物机制更有价值。注意力类处理的趋同演化表明,正在处理的是基本的计算约束,而非工程选择。
大自然通过进化耗费了五亿年探索这些优化景观。通过梯度下降,在短短几年内便重新发现了相似的解决方案。现在的问题是,理解这些数学原理能否指导我们找到超越生物和当前人工方法的更优解决方案。




