理解强化学习的核心概念是掌握这一前沿技术的基础。本文将带领读者从“强化学习究竟是什么”这一最基本的问题出发,逐步深入探讨其高级主题,包括智能体探索、价值与策略,并辨析各种流行的训练方法。在此过程中,读者还将了解到强化学习面临的各种挑战以及研究人员如何应对这些挑战。
强化学习基础
假设需要训练一个AI模型来学习如何穿越障碍物课程。强化学习(RL)是机器学习的一个分支,其模型通过收集经验来学习——即采取行动并观察结果。更具体地说,强化学习由两个核心组成部分构成:智能体(Agent)和环境(Environment)。
智能体
学习过程包含两个不断重复的关键活动:探索(Exploration)和训练(Training)。在探索阶段,智能体通过采取行动并在环境中观察结果来收集经验。随后,在训练活动中,智能体利用这些收集到的经验来提升自身表现。
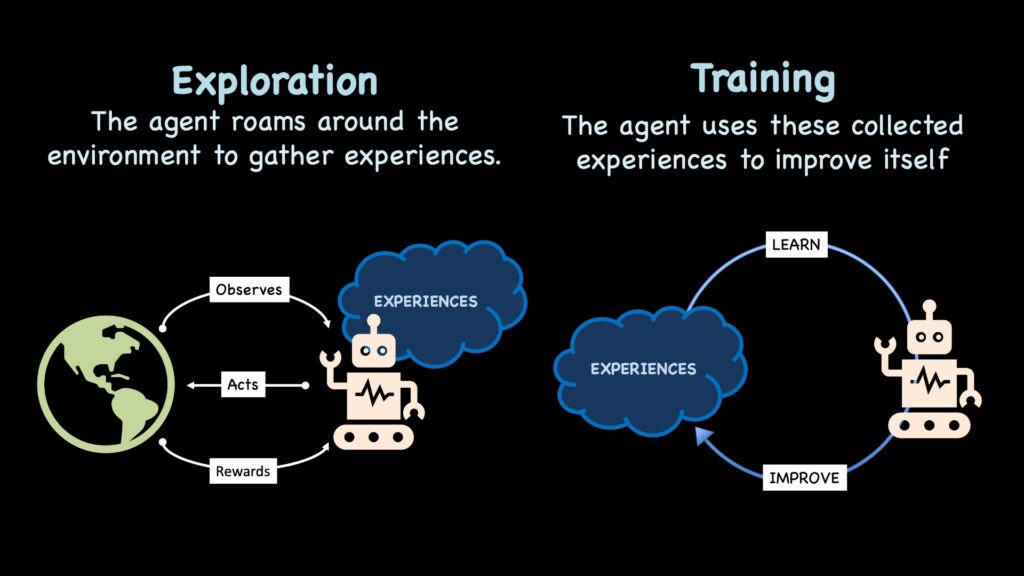
智能体在环境中收集经验,并利用这些经验训练策略。
环境
一旦智能体选择了一个行动,环境就会更新,并根据智能体的表现返回一个奖励。环境设计者负责编程奖励的结构。例如,如果正在开发一个训练AI避开障碍物并到达目标的环境,可以编程环境在智能体接近目标时返回正奖励。但如果智能体与障碍物发生碰撞,则可以编程使其接收一个大的负奖励。
换句话说,当智能体表现“良好”时(例如,获得高正奖励),环境会提供正强化;当智能体表现“不佳”时(例如,获得负奖励),则会给予惩罚。
尽管智能体不了解环境的具体运作方式,但它仍然可以从奖励模式中推断出如何选择最优行动以获得最大奖励。
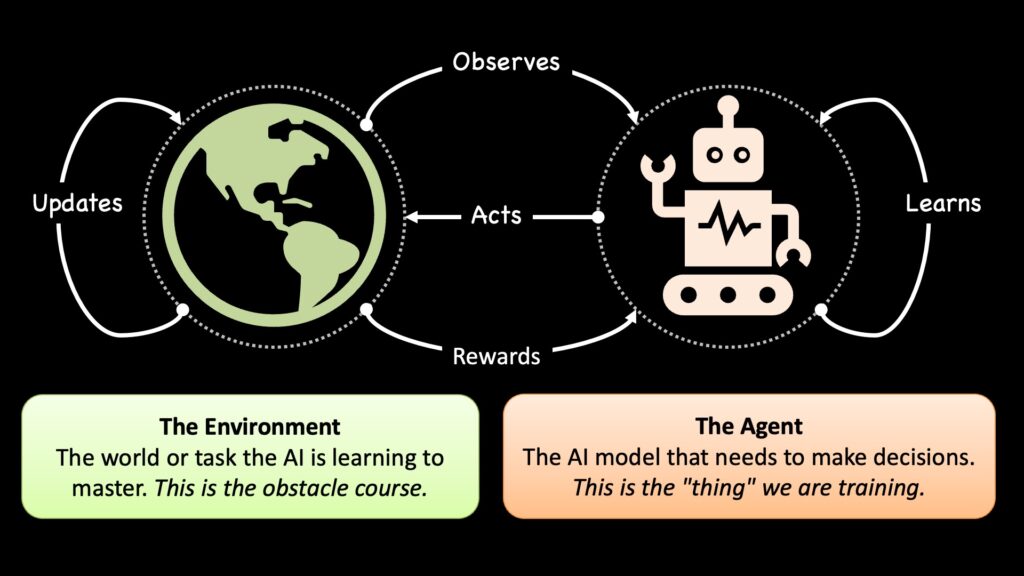
环境和智能体是强化学习的核心。
策略
在每一步中,智能体AI观察环境的当前状态并选择一个行动。强化学习的目标是学习一个从观察到行动的映射,即“给定当前观察到的状态,应该选择什么行动?”
在强化学习术语中,这种从状态到行动的映射也被称为策略(Policy)。
策略定义了智能体在不同状态下的行为方式,而在深度强化学习中,这种功能是通过训练某种深度神经网络来学习的。
强化学习流程
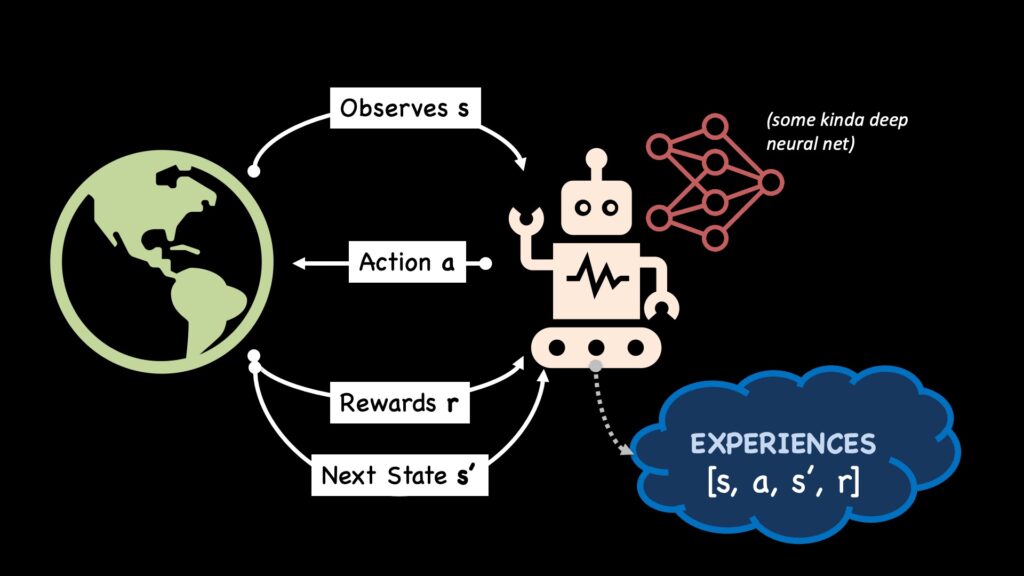
智能体观察状态S,查询网络生成行动A。环境执行行动并返回奖励r和下一个状态s’。这个过程持续到回合终止。智能体采取的每一步都将用于训练其策略网络。
理解智能体、策略和环境之间的区别及其相互作用,对于理解强化学习至关重要:
- 智能体是学习者,在环境中探索并采取行动。
- 策略是智能体根据给定状态决定采取何种行动的战略(通常是一个神经网络)。在强化学习中,最终目标就是训练这个策略。
- 环境是与智能体交互的外部系统,它以奖励和新状态的形式提供反馈。
可以记住以下简洁的定义:
在强化学习中,智能体遵循策略在环境中选择行动。
观察与行动
智能体通过一系列的“步骤”来探索环境。每一步都是一个决策。智能体观察环境的状态,决定一个行动,接收一个奖励,并观察下一个状态。本节将深入探讨观察与行动的含义。
观察
观察是智能体从环境中“看到”的内容——它接收到的关于环境当前状态的信息。在一个障碍物导航环境中,观察可能是激光雷达(LiDAR)投影以检测障碍物。对于Atari游戏,它可能是最近几帧像素的历史记录。对于文本生成,它可能是迄今为止已生成词元(token)的上下文。在国际象棋中,它则是所有棋子的位置以及轮到谁移动等信息。
理想情况下,观察应包含智能体采取行动所需的所有信息。
行动空间是智能体可以采取的所有可用决策的集合。行动可以是离散的,也可以是连续的。离散行动空间是指智能体必须从特定类别的决策集中进行选择。例如,在Atari游戏中,行动可能是Atari手柄的按钮。对于文本生成,它是在模型词汇表中所有词元中进行选择。在国际象棋中,它可能是一个可用的移动列表。

强化学习智能体学习导航障碍物课程时所做的观察和选择的行动示例。
环境设计者也可以选择连续行动空间,其中智能体生成连续值以在环境中采取“步骤”。例如,在障碍物导航示例中,智能体可以选择X和Y方向的速度,以实现对移动的精细控制。在人类角色控制任务中,行动通常是输出角色骨架中每个关节的扭矩或目标角度。
最重要的启示
然而,有一个非常重要的概念需要理解:对于智能体和策略而言,环境及其具体细节可以是一个完全的黑箱。智能体将接收向量状态信息作为观察,生成一个行动,接收一个奖励,并随后从中学习。
因此,可以将智能体和环境视为两个独立的实体。环境定义了状态空间、行动空间、奖励策略和规则。
这些规则与智能体如何探索以及如何根据收集到的经验训练策略是分离的。
在研究论文时,明确正在阅读的是强化学习的哪个方面非常重要。它是一个新的环境吗?它是一个新的策略训练方法吗?它是一个探索策略吗?根据答案,可以将其他方面视为黑箱。
探索
智能体如何探索并收集经验?
每个强化学习算法都必须解决训练强化学习智能体时最大的困境之一——探索与利用(exploration vs exploitation)。
探索意味着尝试新行动以收集有关环境的信息。 想象一下,玩家正在学习如何在困难的视频游戏中与一个Boss战斗。最初,会尝试不同的方法、不同的武器、法术,甚至随机行动,只是为了看看什么有效,什么无效。
然而,一旦开始看到一些奖励,比如持续对Boss造成伤害,就会停止探索,并开始利用已经掌握的策略。利用意味着贪婪地选择认为能获得最佳奖励的行动。
一个好的强化学习探索策略必须在探索和利用之间取得平衡。
一种流行的探索策略是ε-贪婪(Epsilon-Greedy),其中智能体在部分时间(由参数ε定义)采取随机行动进行探索,而在其余时间则利用其已知最佳行动。这个ε值通常在开始时较高,并随着智能体学习而逐渐降低,以偏向利用。
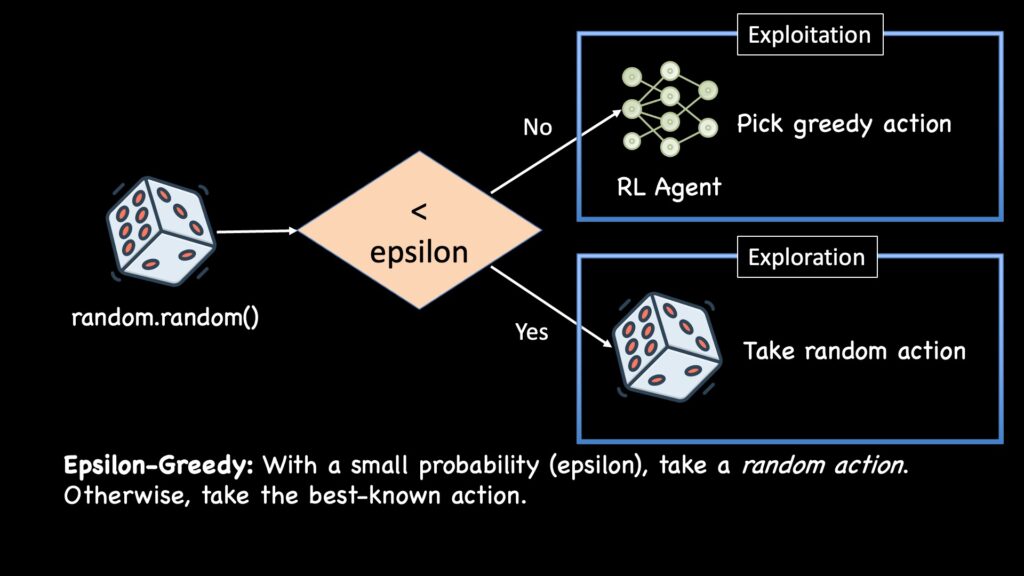
ε-贪婪是一种探索方法,强化学习智能体时不时会选择一个随机行动。
ε-贪婪只适用于离散行动空间。在连续空间中,探索通常通过两种流行方式处理。一种是向智能体决定的行动中添加少量随机噪声。另一种流行技术是向损失函数中添加熵奖励(entropy bonus),这鼓励策略对其选择保持不确定性,从而自然地导致更多样化的行动和探索。
其他鼓励探索的方法包括:
- 设计环境以在回合开始时使用随机状态初始化。
- 内在探索方法,智能体出于自身“好奇心”采取行动。像Curiosity和RND这样的算法会奖励智能体访问新颖状态或采取结果难以预测的行动。
训练算法
强化学习中的大多数研究论文和学术主题都围绕优化智能体选择行动的策略。优化算法的目标是学习能够最大化长期预期奖励的行动。
接下来将逐一探讨不同的算法选择。
基于模型与免模型
智能体已经探索了环境并收集了大量经验。接下来该怎么做?
智能体是直接从这些经验中学习如何行动?还是首先尝试对环境的动力学和物理特性进行建模?
一种方法是基于模型的学习(Model-Based Learning)。在这里,智能体首先利用其经验来构建自己的内部模拟,或称世界模型。该模型学习预测其行动的后果,即,给定一个状态和行动,结果将是下一个状态和奖励。一旦拥有了这个模型,它就可以完全在自己的“想象”中进行练习和规划,运行数千次模拟以找到最佳策略,而无需在现实世界中采取任何冒险的步骤。
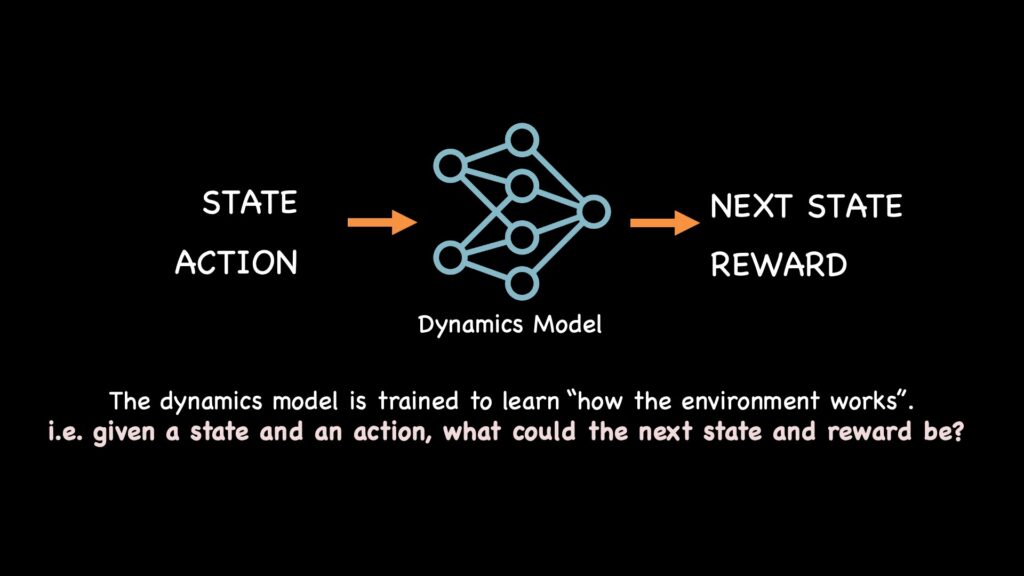
基于模型的强化学习学习一个单独的模型来了解环境的工作原理。
这在收集真实世界经验成本高昂的环境中特别有用,例如机器人学或自动驾驶汽车。基于模型强化学习的例子包括:Dyna-Q、World Models、Dreamer等。
第二种方法称为免模型学习(Model-Free Learning)。这正是本文其余部分将要讨论的内容。在这种方法中,智能体将环境视为一个黑箱,并直接从收集到的经验中学习策略。下一节将更详细地探讨免模型强化学习。
基于价值的学习
免模型强化学习算法主要有两种方法:
基于价值的算法学习评估每个状态有多好。基于策略的算法则直接学习如何在每个状态下行动。
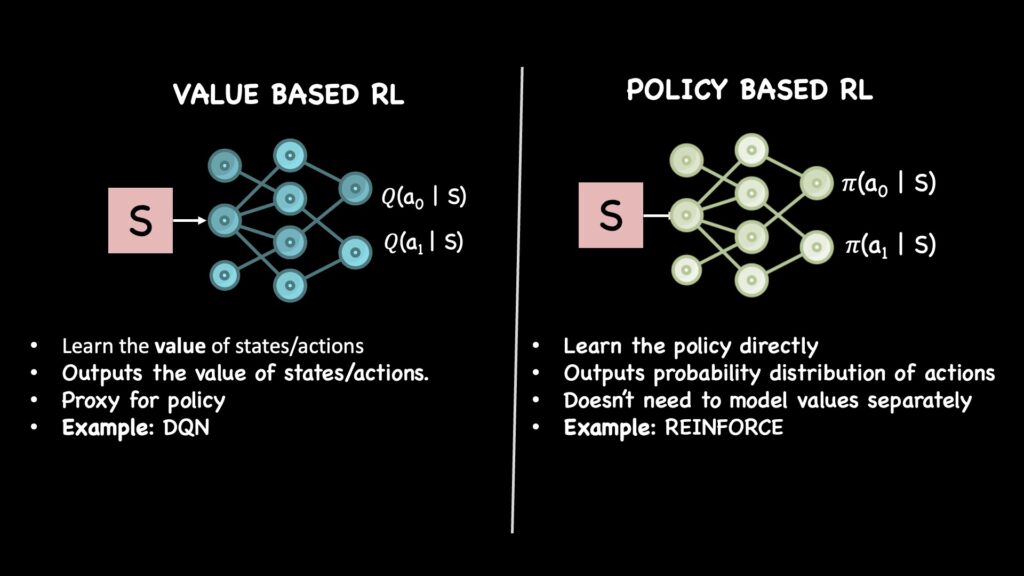
基于价值与基于策略的方法对比。
在基于价值的方法中,强化学习智能体学习处于特定状态的“价值”。状态的价值字面上意味着该状态有多“好”。直观地说,如果智能体知道哪些状态是好的,它就可以更频繁地选择导致这些状态的行动。
幸运的是,有一种数学方法可以实现这一点——贝尔曼方程(Bellman Equation)。
V(s) = r + γ * max V(s’)。
这个递归方程基本表达了:状态s的价值V(s)等于处于该状态的即时奖励r,加上智能体可以从s达到的最佳下一个状态s’的价值。Gamma (γ)是一个折扣因子(介于0和1之间),它降低了下一个状态的“好”程度。它本质上决定了智能体对遥远未来的奖励与即时奖励的重视程度。接近1的γ使智能体“目光长远”,而接近0的γ使智能体“目光短浅”,几乎只贪婪地关心下一个奖励。
Q-学习
理解了状态价值的直观概念,那么如何利用这些信息来学习行动呢?Q-学习方程给出了答案。
Q(s, a) = r + γ * max_a Q(s’, a’)
Q-值Q(s,a)是状态s中行动a的“质量价值”。上述方程基本阐述了:在状态s中采取行动a的质量,等于从状态s获得的即时奖励r,加上下一个最佳行动的折扣质量价值。
总结如下:
- Q-值是每个状态中每个行动的质量价值。
- V-值是特定状态的价值;它等于该状态中所有行动的最大Q-值。
- 策略π在特定状态下是具有最高Q-值的行动。
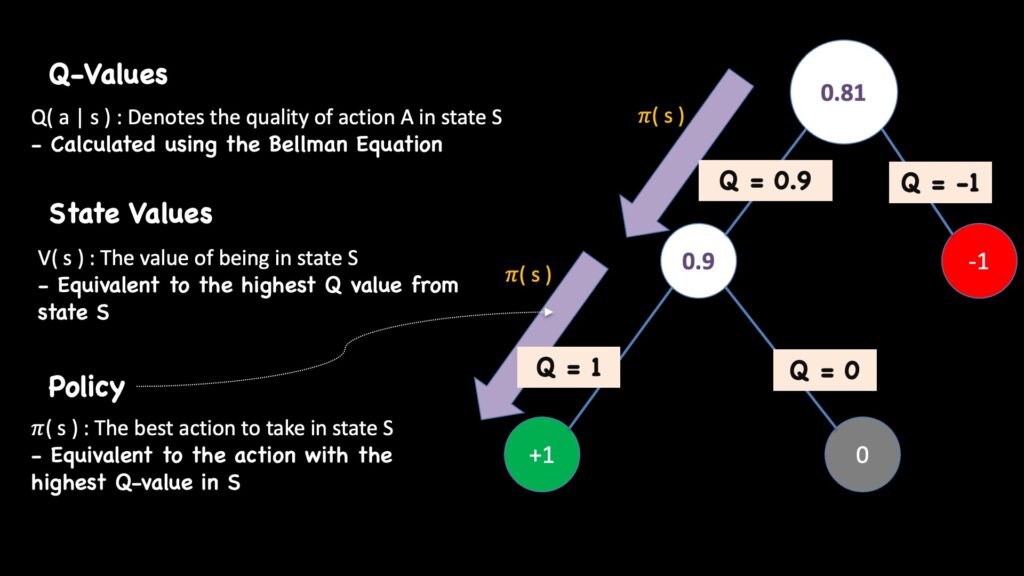
Q-值、状态价值和策略之间存在着深刻的相互联系。
要了解更多关于Q-学习的信息,可以研究深度Q网络(Deep Q Networks)及其后代,如双深度Q网络(Double Deep Q Networks)和决斗深度Q网络(Dueling Deep Q Networks)。
基于价值的学习通过学习处于特定状态的价值来训练强化学习智能体。然而,是否存在一种无需显式学习状态价值就能直接学习最优行动的方法?答案是肯定的。
策略学习方法直接学习最优行动策略,而无需明确学习状态价值。在学习这些方法之前,必须先理解另一个重要的概念:时序差分学习与蒙特卡洛采样。
时序差分学习与蒙特卡洛采样
智能体如何整合未来的经验来进行学习?
在时序差分(Temporal Difference, TD)学习中,智能体在每一步之后都会使用贝尔曼方程更新其价值估计。它通过观察自己对下一个状态Q-值的估计来实现这一点。这种策略被称为1步TD学习,或一步时序差分学习。它迈出一步,然后根据过去的估计更新学习。

在时序差分学习中,智能体迈出一步,并利用下一个状态的价值估计。
第二种方法称为蒙特卡洛(Monte-Carlo)采样。在这种方法中,智能体等待整个回合结束才进行任何更新。然后它使用该回合的完整回报:
Q(s,a) = r₁ + γr₂ + γ²r₃ + … + γⁿrₙ

在蒙特卡洛采样中,智能体完成整个回合,以根据实际奖励计算估计值。
时序差分学习与蒙特卡洛采样的权衡
时序差分学习非常实用,因为智能体可以在完成一个回合之前,从每一步中学习一些东西。这意味着可以长时间保存收集到的经验,并即使在旧经验上也能继续使用新的Q-值进行训练。然而,时序差分学习受到智能体当前状态估计的严重偏差影响。如果智能体的估计是错误的,它将不断强化这些错误的估计。这被称为“自举问题(bootstrapping problem)”。
另一方面,蒙特卡洛学习总是准确的,因为它使用来自实际回合的真实回报。但在大多数强化学习环境中,奖励和状态转换可能是随机的。此外,随着智能体探索环境,其自身行动也可能是随机的,因此在回溯过程中访问的状态也是随机的。这导致纯粹的TD学习方法面临高方差问题,因为不同回合的回报可能差异巨大。
策略梯度
现在,已经理解了时序差分学习与蒙特卡洛采样的概念,是时候回到基于策略的学习方法了。
回想一下,像DQN这样的基于价值的方法必须首先明确计算每个可能行动的价值或Q-值,然后选择最佳行动。但跳过这一步是可能的,而像REINFORCE这样的策略梯度方法正是这样做的。
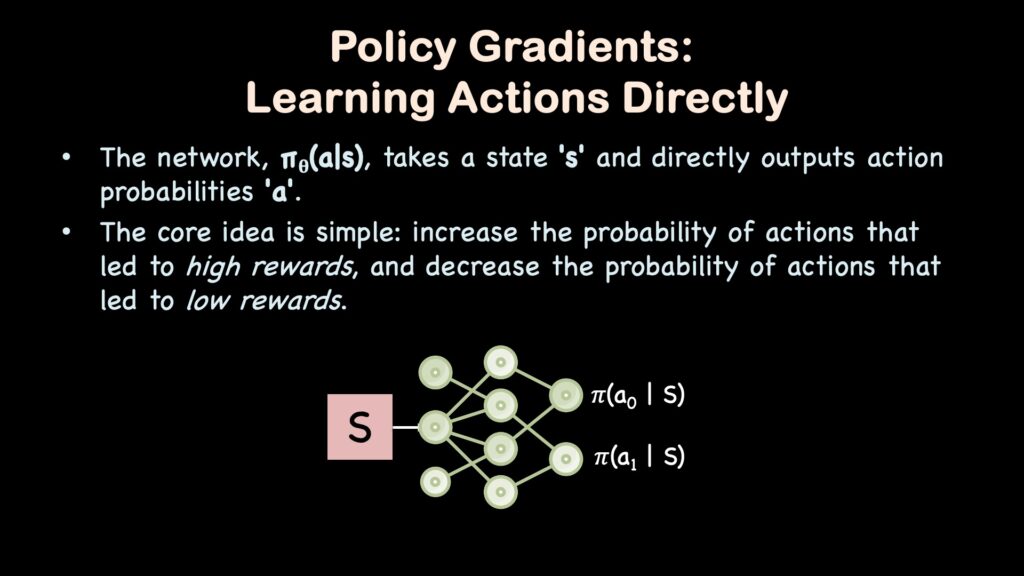
策略梯度方法将状态作为输入,并输出采取行动的概率。
在REINFORCE中,策略网络输出每个行动的概率,并通过训练使其增加导致良好结果的行动的概率。对于离散空间,策略梯度方法将每个行动的概率作为分类分布输出。对于连续空间,策略梯度方法将其作为高斯分布输出,预测行动向量中每个元素的均值和标准差。
那么问题是,如何准确地训练这样一个直接从状态预测行动概率的模型?
这就是策略梯度定理(Policy Gradient Theorem)的用武之地。本文将直观地解释其核心思想。
- 策略梯度模型在文献中通常表示为πtheta(a|s)。其中,theta表示神经网络的权重。πtheta(a|s)是神经网络theta在状态s中预测行动a的概率。
- 从一个新初始化的策略网络开始,让智能体执行一个完整的 эпизод并收集所有奖励。
- 对于智能体采取的每个行动,计算其之后获得的总折扣回报。这通过蒙特卡洛方法完成。
- 最后,为了实际训练模型,策略梯度定理要求最大化下方图中提供的公式。
- 如果回报很高,这次更新将通过增加π(a|s)使该行动在未来更可能发生。如果回报是负的,这次更新将通过减少π(a|s)使该行动的可能性降低。

策略梯度。
Q-学习与REINFORCE的区别
Q-学习与REINFORCE的核心区别之一在于,Q-学习使用1步时序差分学习,而REINFORCE使用蒙特卡洛采样。
通过使用1步时序差分,Q-学习必须确定每个状态-行动可能性的质量价值Q。因为在1步时序差分中,智能体可以在环境中只迈出一步,并确定该状态的质量分数。
另一方面,蒙特卡洛采样中,智能体无需依赖估计器进行学习。相反,它使用在探索过程中观察到的实际回报。这使得REINFORCE“无偏”,但缺点是它需要多个样本才能正确估计轨迹的价值。此外,智能体在完全完成一个轨迹(即达到终止状态)之前无法训练,并且在策略网络更新后无法重用轨迹。
在实践中,REINFORCE常导致稳定性问题和样本效率低下。接下来将探讨Actor-Critic如何解决这些局限性。
优势Actor-Critic
如果尝试在大多数复杂问题上使用普通的REINFORCE,它会遇到困难,原因有二。
首先,因为它是一种蒙特卡洛采样方法,它遭受高方差问题。其次,它没有基线概念。试想一个总是给予正奖励的环境,那么回报永远不会是负的,REINFORCE将增加所有行动的概率,尽管是以不成比例的方式。
不应该仅仅因为获得正分数就奖励行动。而是要奖励那些比平均水平更好的行动。
这就是“优势(advantage)”概念变得重要的原因。不再仅仅使用原始回报来更新策略,而是减去该状态的预期回报。因此,新的更新信号变为:
优势 = 获得的回报 – 预期的回报
虽然优势为观察到的回报提供了基线,但也需要讨论Actor-Critic方法的概念。
Actor-Critic结合了基于价值方法(如DQN)和基于策略方法(如REINFORCE)的最佳特性。Actor-Critic方法训练一个独立的“评论家(critic)”神经网络,该网络仅用于评估状态,非常类似于前面提到的Q网络。
另一方面,“行动者(actor)”方法则学习策略。
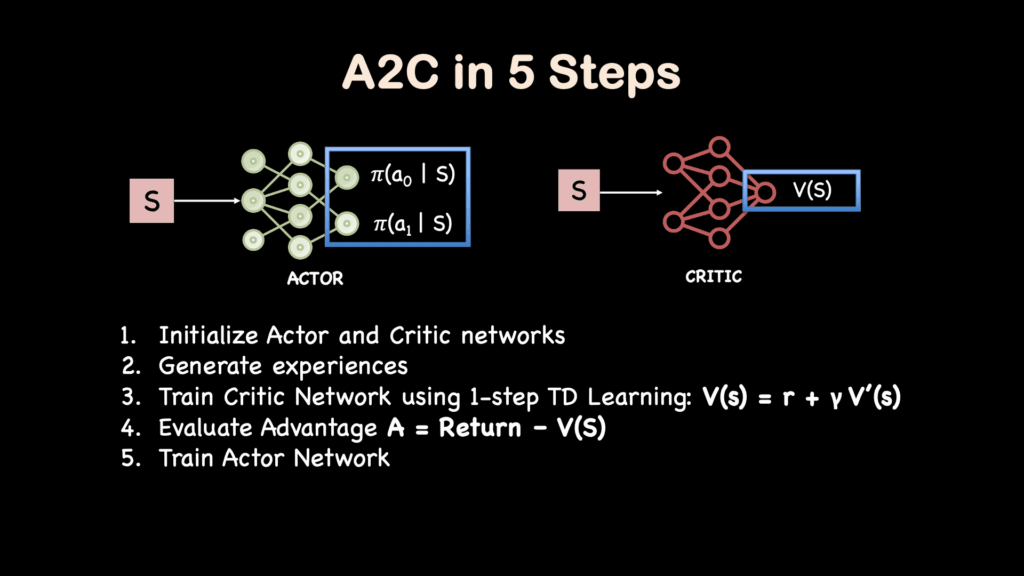
优势Actor-Critic。
结合优势和Actor-Critic,可以理解流行的A2C算法是如何工作的:
- 初始化2个神经网络:策略或行动者网络,以及价值或评论家网络。行动者网络输入状态并输出行动概率。评论家网络输入状态并输出一个代表状态价值的浮点数。
- 通过查询行动者在环境中生成一些回溯(rollouts)。
- 使用时序差分学习或蒙特卡洛学习更新评论家网络。也有更高级的方法,如广义优势估计(Generalized Advantage Estimates),它结合了这两种方法以实现更稳定的学习。
- 通过从评论家网络生成的平均回报中减去观察到的回报来评估优势。
- 最后,使用优势和策略梯度方程更新策略网络。
Actor-Critic方法通过使用价值函数作为基线,解决了策略梯度中的方差问题。PPO(近端策略优化)通过在学习算法中加入“信任区域”概念来扩展A2C,这防止了学习过程中网络权重的过度变化。
总结
每种算法都针对这些问题做出了特定的选择,这些选择会贯穿整个系统,影响从样本效率到稳定性再到实际性能的方方面面。
最终,创建一个强化学习算法就是通过做出这些选择来回答上述问题。DQN选择学习价值。策略方法直接学习策略。蒙特卡洛方法在整个回合结束后使用实际回报进行更新——这使得它们无偏,但由于强化学习探索的随机性而具有高方差。时序差分学习则选择在每一步基于智能体自身的估计进行学习。Actor-Critic方法通过分别学习行动者网络和评论家网络来结合DQN和策略梯度。
本文未能涵盖所有内容,但这为开始学习强化学习奠定了坚实的基础。