在之前的博客文章中,我们深入探讨了如何利用CrewAI和Streamlit构建一个多智能体SQL助手。该助手允许用户通过自然语言查询SQLite数据库。人工智能代理会根据用户输入生成SQL查询,进行审查,并在执行前检查合规性以获取结果。文章还实现了“人在回路”的检查点机制以保持控制,并透明地展示了每次查询相关的LLM成本,以便进行成本控制。尽管该原型在小型演示数据库上表现出色并生成了良好结果,但对于真实世界的复杂数据库而言,这种方法显然存在局限。
原先的设置会将整个数据库模式作为上下文连同用户输入一并发送给大型语言模型(LLM)。随着数据库模式的日益庞大,传递完整的模式会显著增加令牌使用量,延长响应时间,并提高模型产生幻觉的可能性。因此,需要一种更智能的方式,仅向LLM提供相关的模式片段。这正是检索增强生成(RAG)技术发挥作用的关键。
本博客文章将详细介绍如何构建一个RAG管理器,并为SQL助手添加多种RAG策略,以比较它们在响应时间、令牌使用量等指标上的性能。目前,该助手支持四种RAG策略:
- 无RAG(No RAG): 传递完整模式(作为性能比较的基线)。
- 关键词RAG(Keyword RAG): 利用领域特定的关键词匹配来选择相关表。
- FAISS RAG: 通过FAISS结合
all-MiniLM-L6-v2嵌入,实现语义向量相似性检索。 - Chroma RAG: 一种采用ChromaDB的持久化向量存储解决方案,适用于可扩展的生产级搜索。
在该项目中,主要关注了实用、轻量且经济高效(免费)的RAG技术。用户可以根据自身需求在此基础上添加任意数量的实现,并选择最适合的方案。为了方便实验和分析,文章还构建了一个交互式性能比较工具,用于评估所有四种策略在令牌减少量、表数量、响应时间和查询准确性方面的表现。
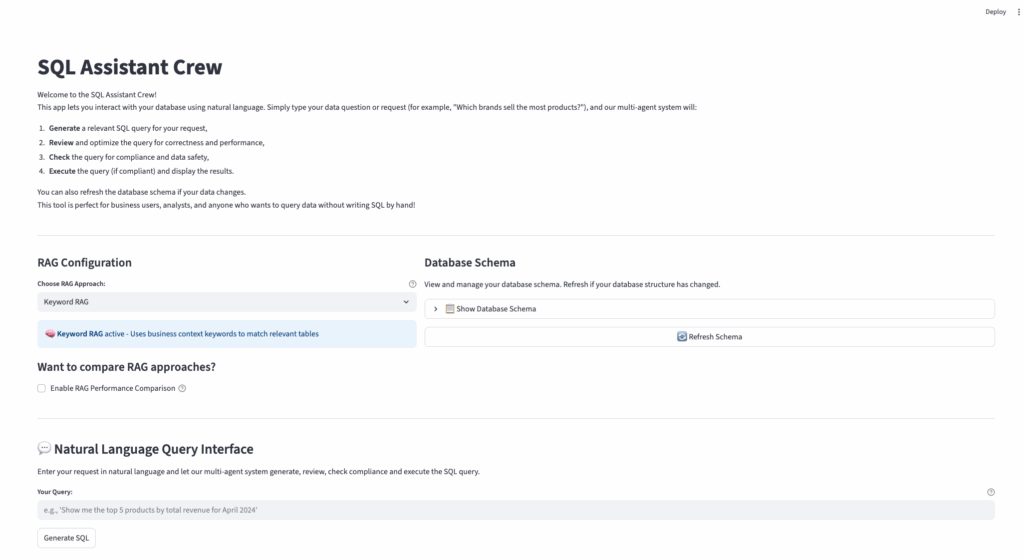
应用截图
构建RAG管理器
rag_manager.py文件包含了RAG管理器的完整实现。首先,创建一个BaseRAG类——这是所有不同RAG策略的通用模板。它确保每个RAG方法都遵循相同的结构。任何新的策略都必须包含两个方法:一个用于根据用户查询获取相关模式的方法,另一个用于解释该方法的用途。通过使用抽象基类(ABC),代码保持了整洁、模块化,并易于未来的扩展。
from typing import Dict, List, Any, Optional
from abc import ABC, abstractmethod
class BaseRAG(ABC):