

随着深度学习模型日益庞大,数据集不断扩展,从业者面临着一个日益普遍的瓶颈:GPU内存带宽。虽然尖端硬件提供了FP8精度以加速训练和推理,但大多数数据科学家和机器学习工程师使用的仍是缺乏此功能的旧款GPU。
正是生态系统中的这一差距,催生了开源库Feather的开发。该库采用基于软件的方法,在广泛可用的硬件上实现了类似FP8的性能提升。开发此工具旨在让更广泛的机器学习社区能够更便捷地进行高效深度学习,并欢迎社区的贡献。
符号与缩写
- FPX: X位浮点数
- UX: X位无符号整数
- GPU: 图形处理器
- SRAM: 静态随机存取存储器(GPU片上缓存)
- HBM: 高带宽内存(GPU显存)
- GEMV: 通用矩阵-向量乘法
开发动机
FP8处理在深度学习领域已被证明是有效的[1];然而,只有特定的近期硬件架构(如Ada和Blackwell)支持它,这限制了从业者和研究人员利用其优势。例如,Nvidia RTX 3050 6GB 笔记本GPU在硬件层面就不支持FP8操作。
受软件加速解决方案(如在缺乏原生硬件加速支持的计算机上进行软件加速渲染)的启发,本文提出了一种能够利用FP8数据类型优势的解决方案。
将FP8和FP16打包进FP32容器
受位操作和打包技术的启发,本文介绍了一种算法,可以将两个FP16或四个FP8打包进一个FP32中。这使得内存占用减少一半或四分之一,从而降低内存占用,仅牺牲少量精度。
有人可能会认为这进行了冗余计算:“打包 -> 加载 -> 解包 -> 计算”。然而,考虑深度学习操作,大多数情况下,这些操作是内存受限而非计算受限的。这与FlashAttention等算法解决的瓶颈相同;但FlashAttention利用分块技术将数据保留在快速的SRAM中,而Feather则通过压缩数据来减少内存流量。
GPU内存层次结构
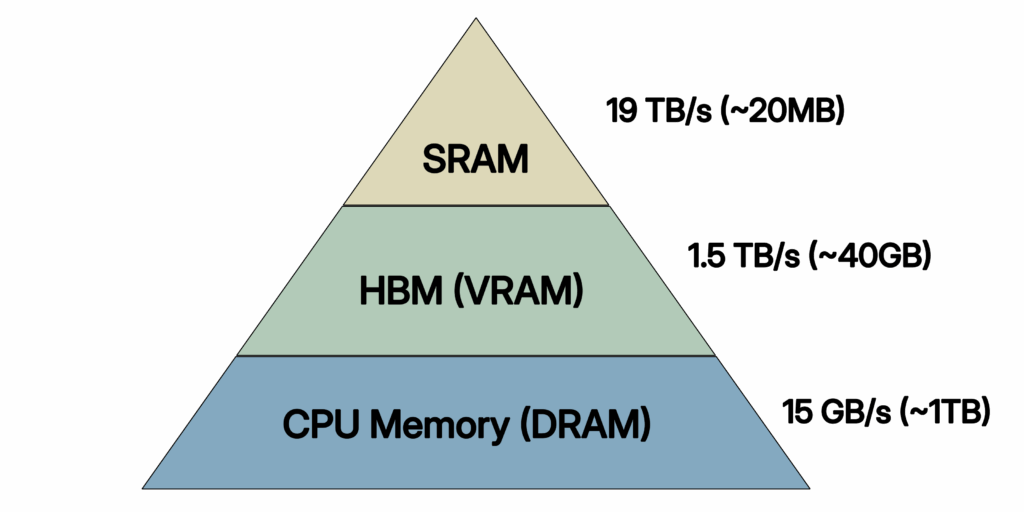
GPU内存层次结构与带宽图表。(改编自Flash Attention)(注:所示数值不代表RTX 3050显卡)
观察此图。SRAM是GPU上访问速度最快、带宽最高的内存区域(寄存器本身除外),但容量有限,通常只有约20MB。HBM可视为GPU的显存,其带宽大约只有SRAM的1/7。
GPU核心的计算速度足够快,可以瞬间完成计算,但它们大部分时间处于空闲状态,等待数据加载和写回完成。这就是所谓的内存受限:瓶颈不在于数学计算,而在于GPU内存层次结构之间的数据传输。
低精度类型与带宽
由于归一化等原因,计算过程中的数值大多被限制在零附近的小范围内。工程师们开发了FP8和FP16等低精度类型,它们允许更高的有效带宽。降低精度如何提高带宽?仔细分析会发现,对于FP16类型,我们实际上在一个数据位宽内加载了两个值;对于FP8类型,则加载了四个值。这是在用精度换取更高的带宽,以应对内存受限的操作。
硬件层面支持
就像AVX-512指令集仅限少数硬件平台支持一样,FP8和FP16指令及寄存器也受限于硬件,仅在近期产品中可用。如果使用的是Nvidia的RTX-30或RTX-20系列GPU,则无法利用这种低精度FP8类型。这正是Feather试图解决的问题。
打包方法
使用位操作符,可以轻松地将FP16类型打包进FP32。算法描述如下。
打包FP16
- 将输入的FP32转换为FP16;这一步可以轻松使用NumPy的astype函数完成。
- 将它们转换为U16,再转换为U32;这将高16位设为0,低16位设为实际的FP16值。
- 使用位操作符左移(LSHIFT)将其中一个值移动16位,然后使用位操作符或(OR)将两者组合。
解包FP16
- 使用位操作符与(AND)和掩码0xFFFF提取低16位。
- 通过右移(RSHIFT)16位提取高16位,然后与掩码0xFFFF进行与(AND)操作。
- 将两个U16值转换回FP16,如果需要则再转换为FP32。
打包FP8
FP8有两种广泛使用的格式——E5M2 和 E4M3。不能直接使用打包两个FP16到FP32的算法,因为CPU本身不支持FP8类型,但支持FP16(半精度);这就是np.float8不存在的原因。
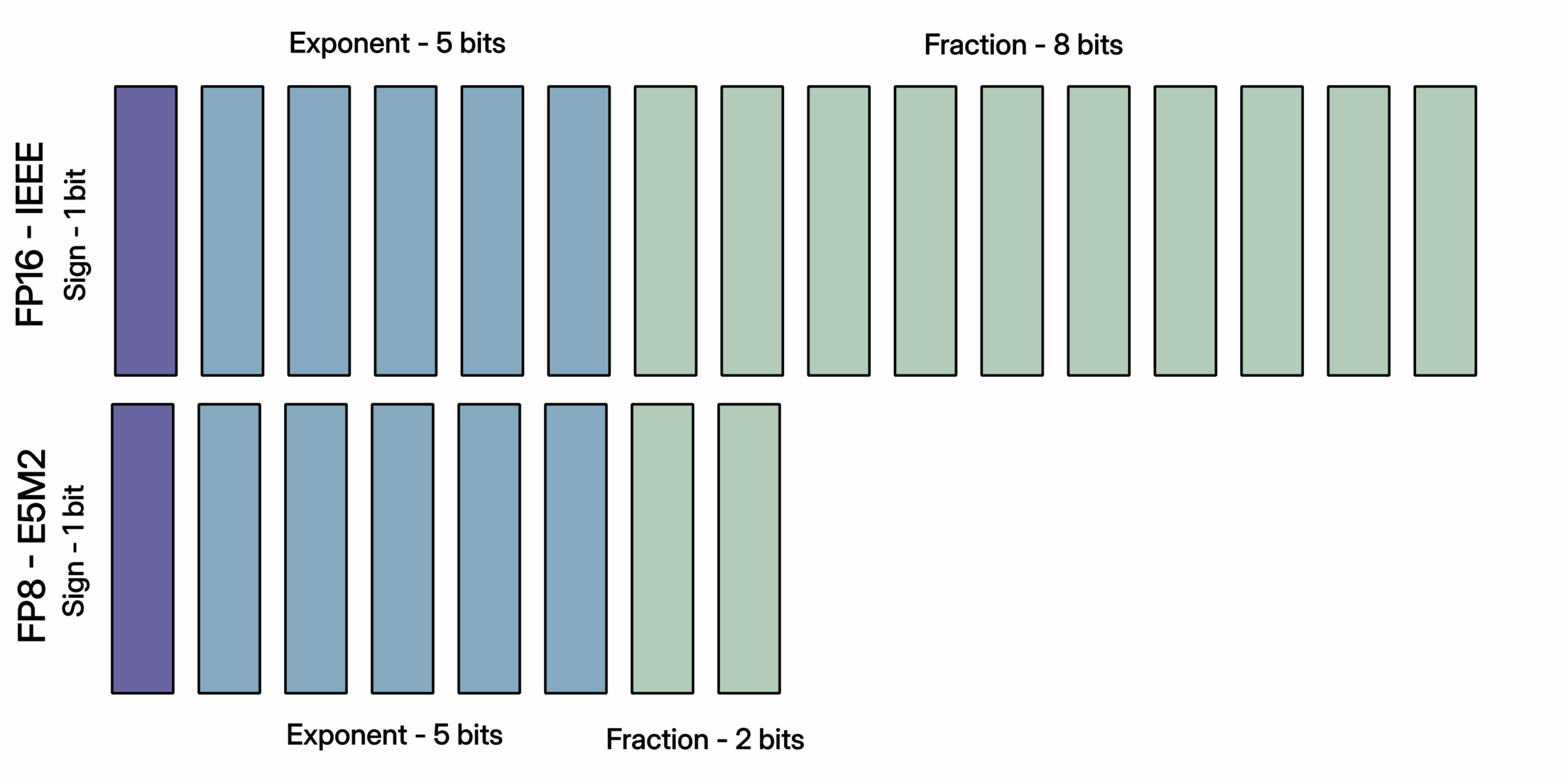
FP8-E5M2 与 FP16 格式(改编自半精度浮点格式)
将FP16转换为FP8-E5M2相对直接,如图所示,因为两者具有相同数量的指数位,仅小数部分不同。
FP8-E5M2打包
- 将输入的FP32转换为FP16;可以使用NumPy的astype函数轻松完成,或者直接输入FP16。
- 转换为U16,左移(LSHIFT)8位,然后右移(RSHIFT)8位以隔离高8位。
- 对所有四个FP32或FP16执行此操作。
- 现在使用左移(LSHIFT)操作符,将它们分别移动0、8、16和24个单位,并使用位操作符或(OR)进行组合。
同样,解包应该是打包的逆过程,相对直接。
打包FP8-E4M3不像打包FP16或FP8-E5M2那样简单直接,因为指数位不匹配。
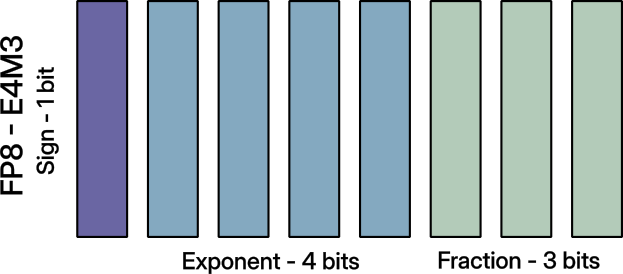
FP8-E4M3格式(改编自迷你浮点)
为了避免从零开始实现,该库使用了ml_dtypes库,该库已经完成了转换的数学运算。
ml_dtypes库为NumPy数组提供了对常用FP8标准(如E5M2和E4M3转换)的支持。使用相同的astype函数,可以像处理FP16类型一样执行转换。算法与打包FP16完全相同,此处不再赘述。
Triton GPU内核
打包之后,需要一个算法(内核)来利用这种打包数据类型并执行计算。将打包数据类型传递给为FP32或FP64实现的内核会导致未定义的计算结果,因为传递的FP32或FP64值已被改变。在CUDA中编写一个接收打包数据类型作为输入的内核并非易事且容易出错。这正是Triton的用武之地;它是一种领域特定语言库,利用自定义中间表示来编写GPU内核。简而言之,它允许直接用Python编写GPU内核,而无需用C语言编写CUDA内核。
Triton内核执行的操作如前所述;算法如下:
- 将打包数组加载到内存中
- 解包内存并将其上转换为FP32以进行累加任务
- 执行计算
需要注意的是,在执行计算时,使用上转换是为了防止溢出。因此,从计算角度来看,并没有优势。然而,从带宽角度来看,我们在不损害带宽的情况下加载了两倍或四倍的内存。
Triton内核实现(伪代码)
@triton.jit
def gemv_fp8_kernel(packed_matrix_ptr, packed_vector_ptr, out_ptr):
# 获取当前要处理的行
row_id = get_program_id()
# 初始化点积累加器
accumulator = 0
# 按块遍历行
for each block in row:
# 加载打包的FP32值(每个包含4个FP8)
packed_matrix = load(packed_matrix_ptr)
packed_vector = load(packed_vector_ptr)
# 将FP32解包为4个FP8值
m_a, m_b, m_c, m_d = unpack_fp8(packed_matrix)
v_a, v_b, v_c, v_d = unpack_fp8(packed_vector)
# 上转换为FP32并计算部分点积
accumulator += (m_a * v_a) + (m_b * v_b) + (m_c * v_c) + (m_d * v_d)
# 存储最终结果
store(out_ptr, accumulator)
性能结果
硬件:NVIDIA GeForce RTX 3050 6GB VRAM
CUDA版本: 13.0
Python版本: 3.13.9
GEMV基准测试(M = 16384, N = 16384)(MxN矩阵)
实现方式 时间(微秒) 加速比
PyTorch (FP32) 5,635 (基线)
Feather (FP8-E4M3) 2,703 2.13倍
Feather (FP8-E5M2) 1,679 3.3倍
理论上可实现的性能提升是4倍;相比之下,3.3倍是非常好的结果,剩余的开销主要来自打包/解包操作和内核启动成本。
E5M2比E4M3更快,因为解包更容易,但E4M3提供了更好的精度。然而,E4M3的解包过程要复杂得多(Feather使用单独的GPU内核来解包E4M3格式)。
Flash Attention基准测试(序列长度 = 8192, 嵌入维度 = 512)
实现方式 时间(微秒) 加速比
PyTorch (FP32) 33,290 (基线)
Feather (FP8-E5M2) 9,887 ~3.3倍
准确性与精度
使用随机矩阵(在范围[-3, 3]内的整数分布和标准正态分布)进行测试表明,对于深度学习操作,E4M3和E5M2都能将数值结果保持在实用的容差范围内。对于典型的工作负载大小,累积误差是可控的;然而,需要严格数值精度的用户应验证其特定用例。
何时使用Feather?
Feather的用例并不局限,在FP8打包和解包具有优势的场景下均可使用,例如:
- 大型矩阵-向量乘积,其中加载和卸载是瓶颈。
- 类似注意力机制的内存受限内核。
- 在原生RTX 30或20系列上进行推理或微调。
- 批量处理,其中打包开销被分摊。
何时不应使用Feather?
- 拥有RTX 40系列或H100 GPU时(原生FP8更快)。
- 工作负载是计算受限而非带宽或内存受限时。
- 需要保证精度时。
Feather的局限性
Feather目前处于原型早期阶段,有几个方面有待改进。
- 操作支持有限;目前Feather仅支持点积、GEMV子程序和FlashAttention。
- 完整机器学习工作负载的准确性验证;目前Feather的准确性仅针对操作进行了验证,而非端到端的机器学习工作负载。
- 集成度目前有限;Feather是一个独立的实现。与PyTorch集成并支持自动微分将使其更适合生产环境。
该项目是开源的,欢迎社区贡献!只需按照GitHub上的说明即可尝试代码。





