

在本系列关于联邦学习的技术解析中,前篇已系统阐述联邦学习的基本原理。建议技术背景薄弱的读者优先阅读首篇基础理论篇了解框架机制。为便于快速回顾核心概念,这里提供基于marimo开发的交互式应用,用户可通过该工具进行本地模型训练,并观察联邦平均算法(FedAvg)如何提升全局模型性能。
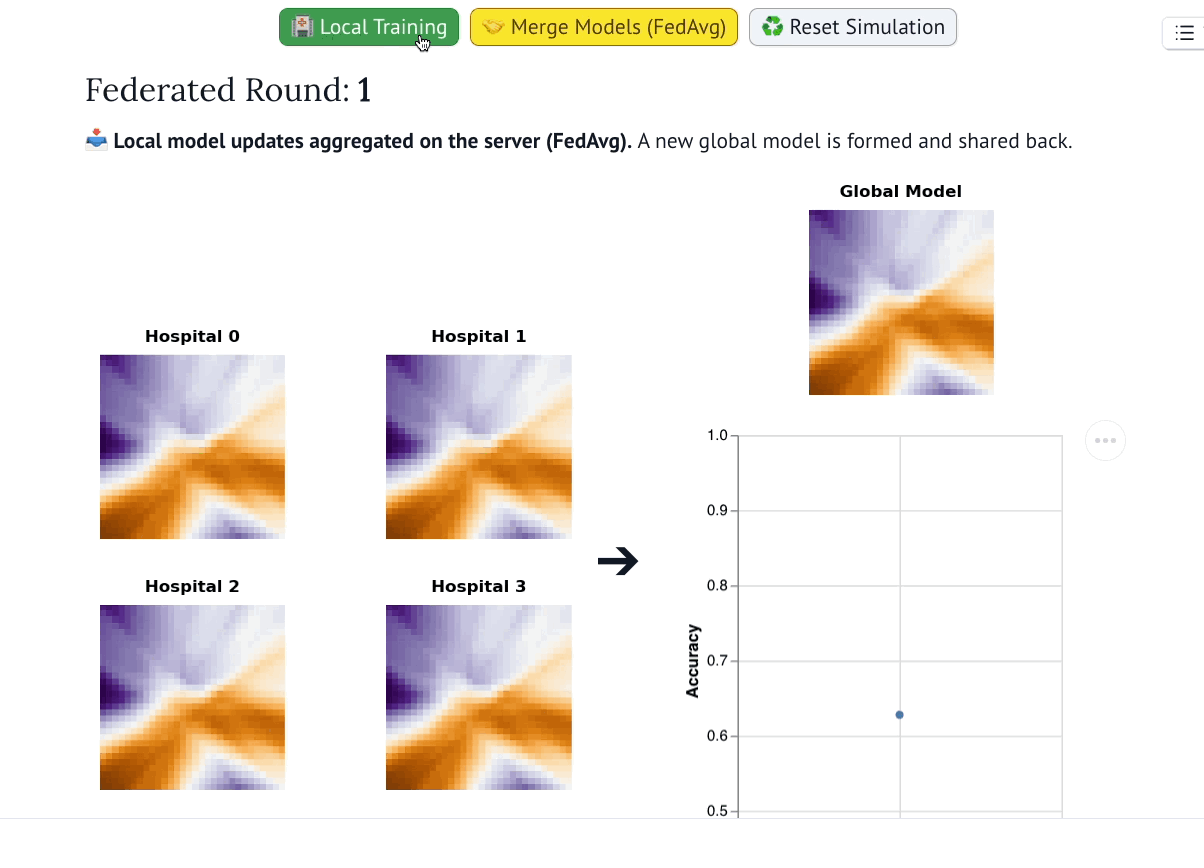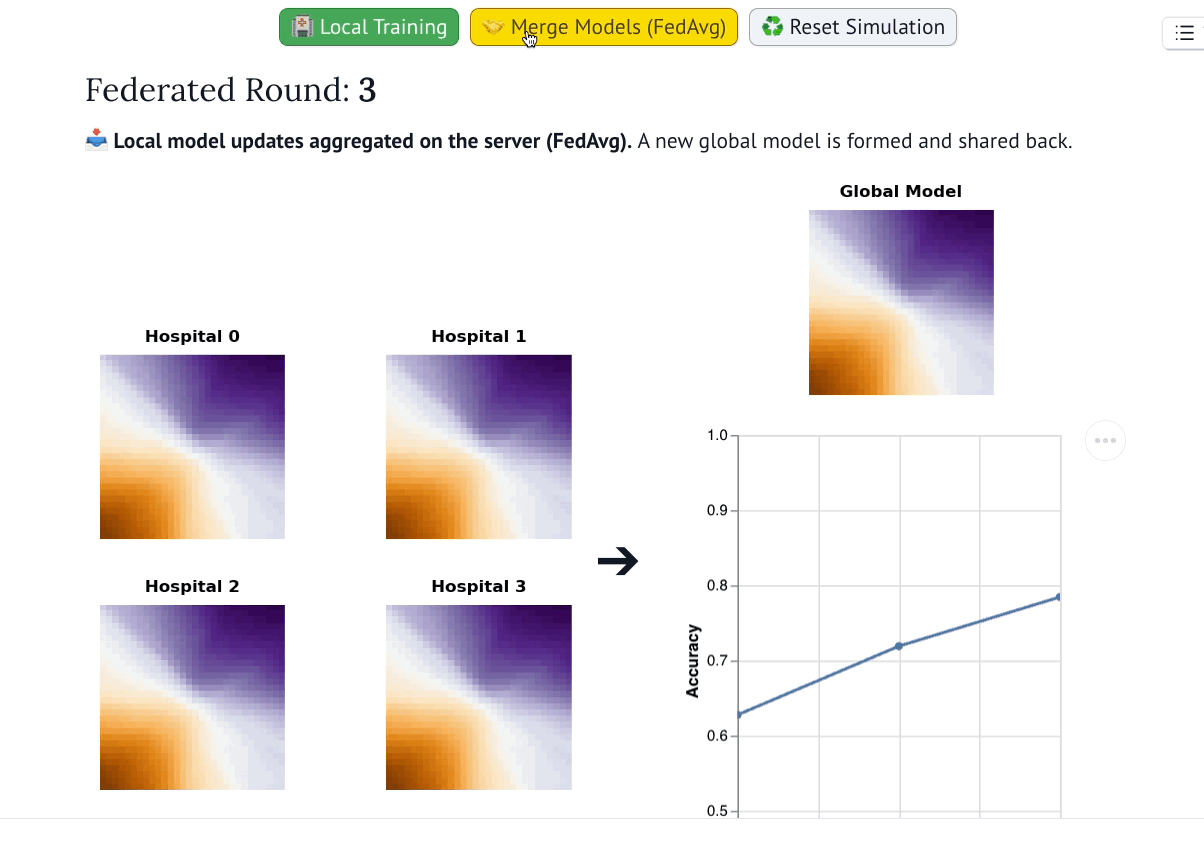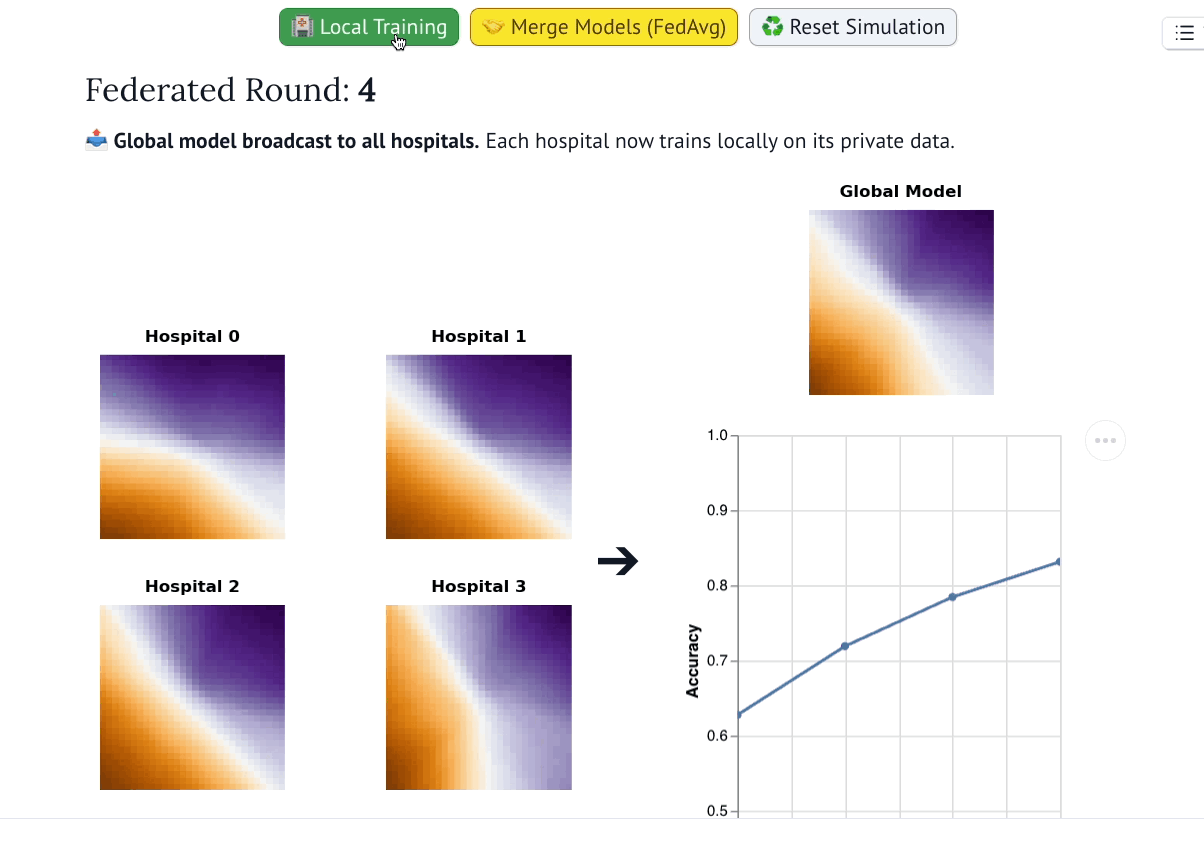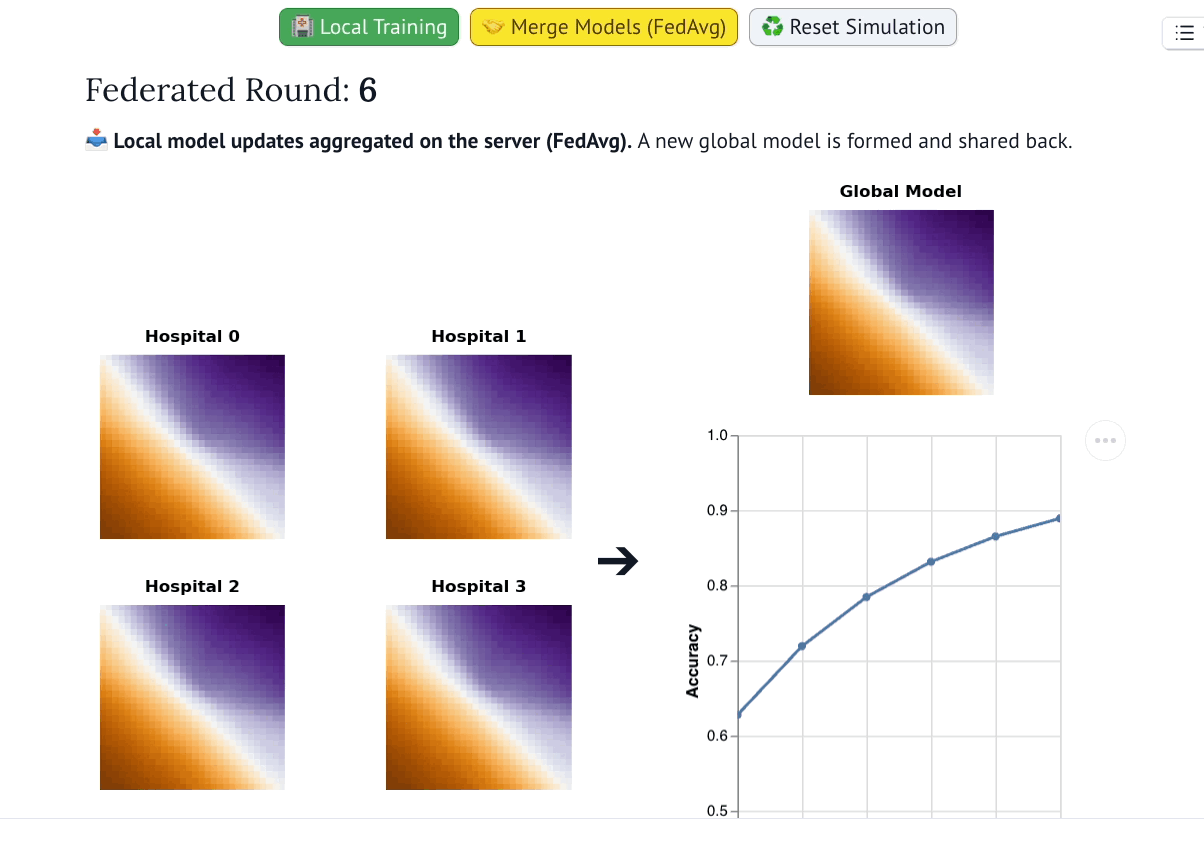
该可视化系统展示了全局模型在联邦训练轮次中的演化过程(灵感源自AI Explorables)。
下文将聚焦Flower框架的技术实现,系统性解析联邦学习系统的构建方案。
数据分布偏差对模型性能的影响
前文提及的英国NHS新冠筛查项目印证,当模型仅用单个医院数据训练时,将过度学习特定机构的数据特征导致泛化能力下降。为量化这一影响,现通过具体实验进行验证。
借鉴DeepLearning.AI的Flower实验室课程方法,该实验采用MNIST数据集进行三类划分,模拟三家医院的数据隔离场景:
- 使用Flower Datasets库优化联邦场景下的数据处理流程
数据集分割方案
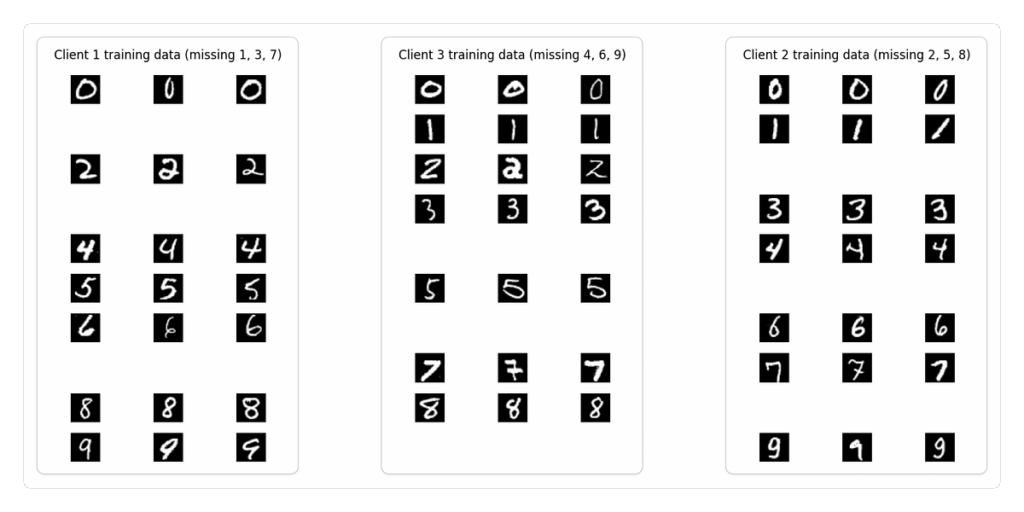 将MNIST分为三个子集:
将MNIST分为三个子集:
· 数据集1缺失数字1/3/7
· 数据集2缺失数字2/5/8
· 数据集3缺失数字4/6/9
局部训练结果分析
采用双全连接层的PyTorch架构进行10轮训练后,各模型均呈现收敛趋势:
但当测试全域数据时,准确率仅为65%-70%;针对缺失数字的测试子集,识别准确率骤降至0%: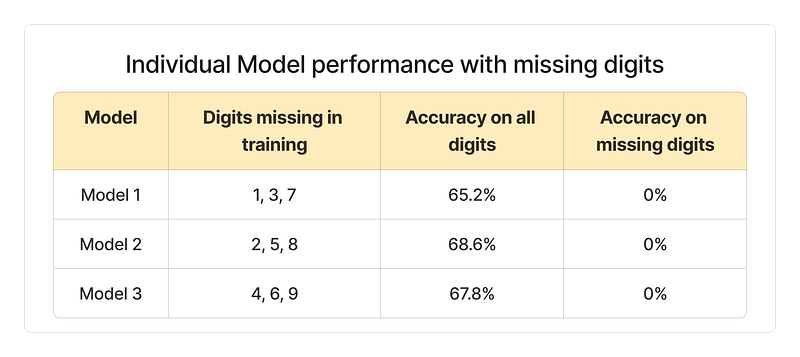
混淆矩阵揭示系统的误判规律,未训练数字始终被错误归类到形态近似的类别: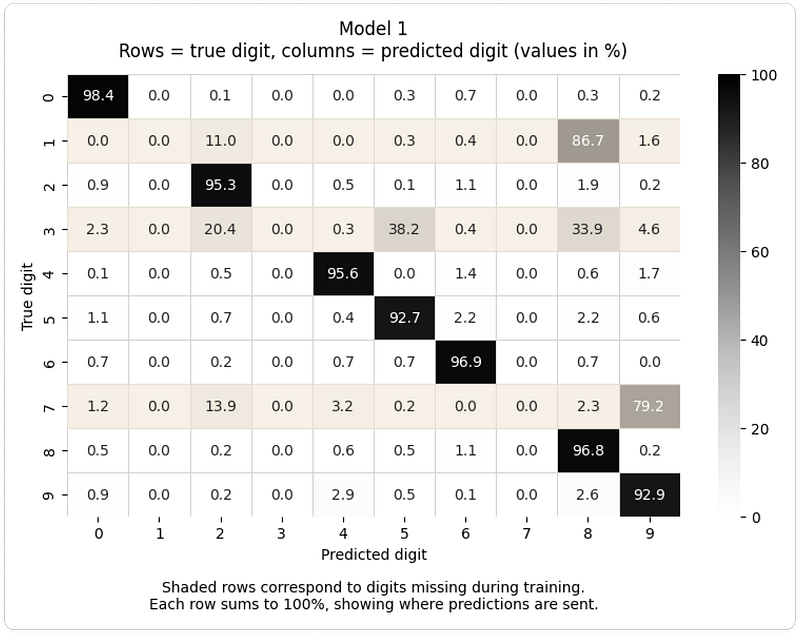
Flower框架技术解析
Flower框架作为开源联邦学习系统,支持PyTorch、TensorFlow等多平台开发。其核心架构包含两个启动命令:
# 创建联邦学习项目脚手架
flwr new @flwrlabs/quickstart-pytorch
# 执行联邦训练
flwr run .项目结构如下:
quickstart-pytorch
├── client_app.py # 客户端逻辑
├── server_app.py # 服务端协调
└── task.py # 模型与数据配置训练流程可视化
联邦训练效果验证
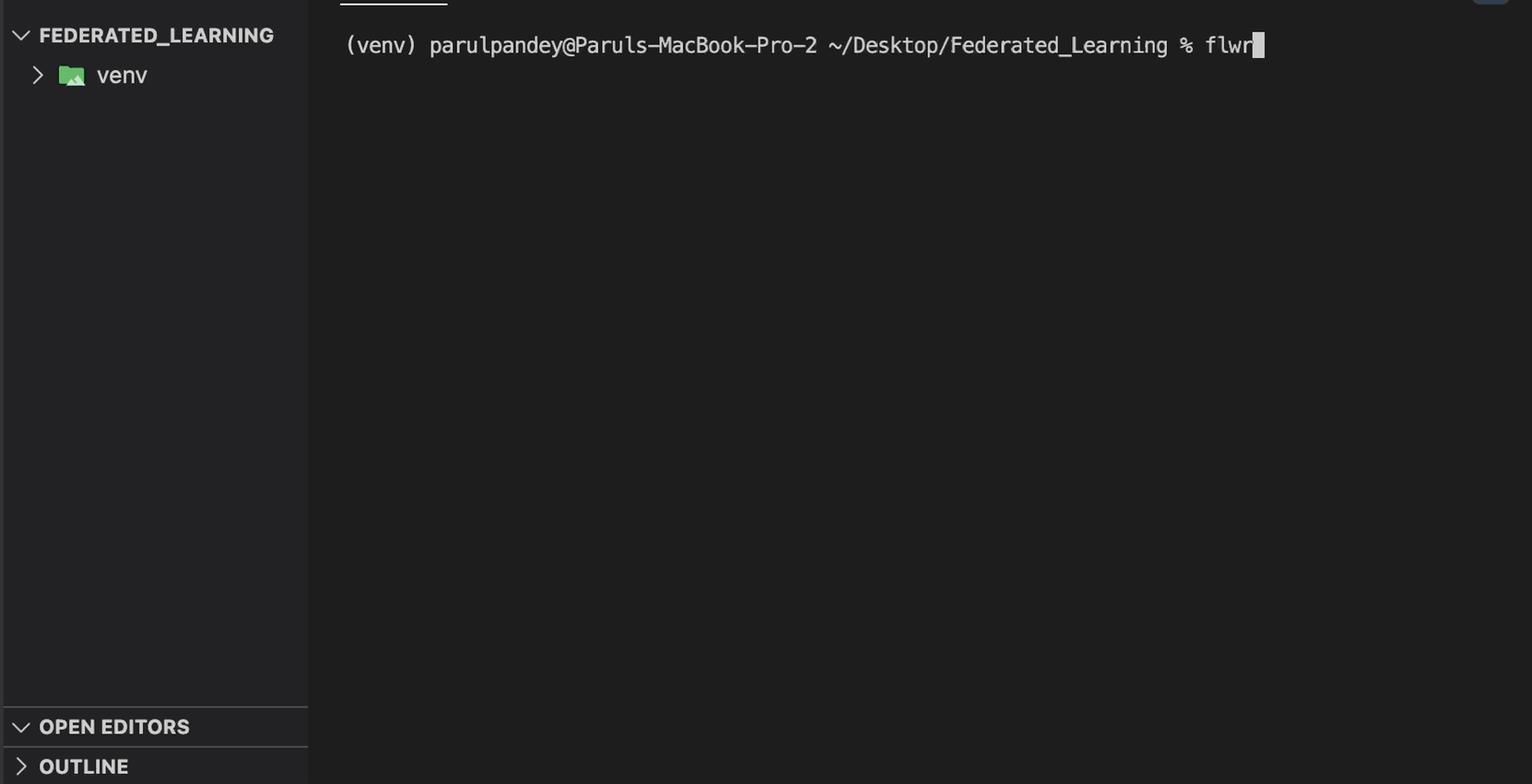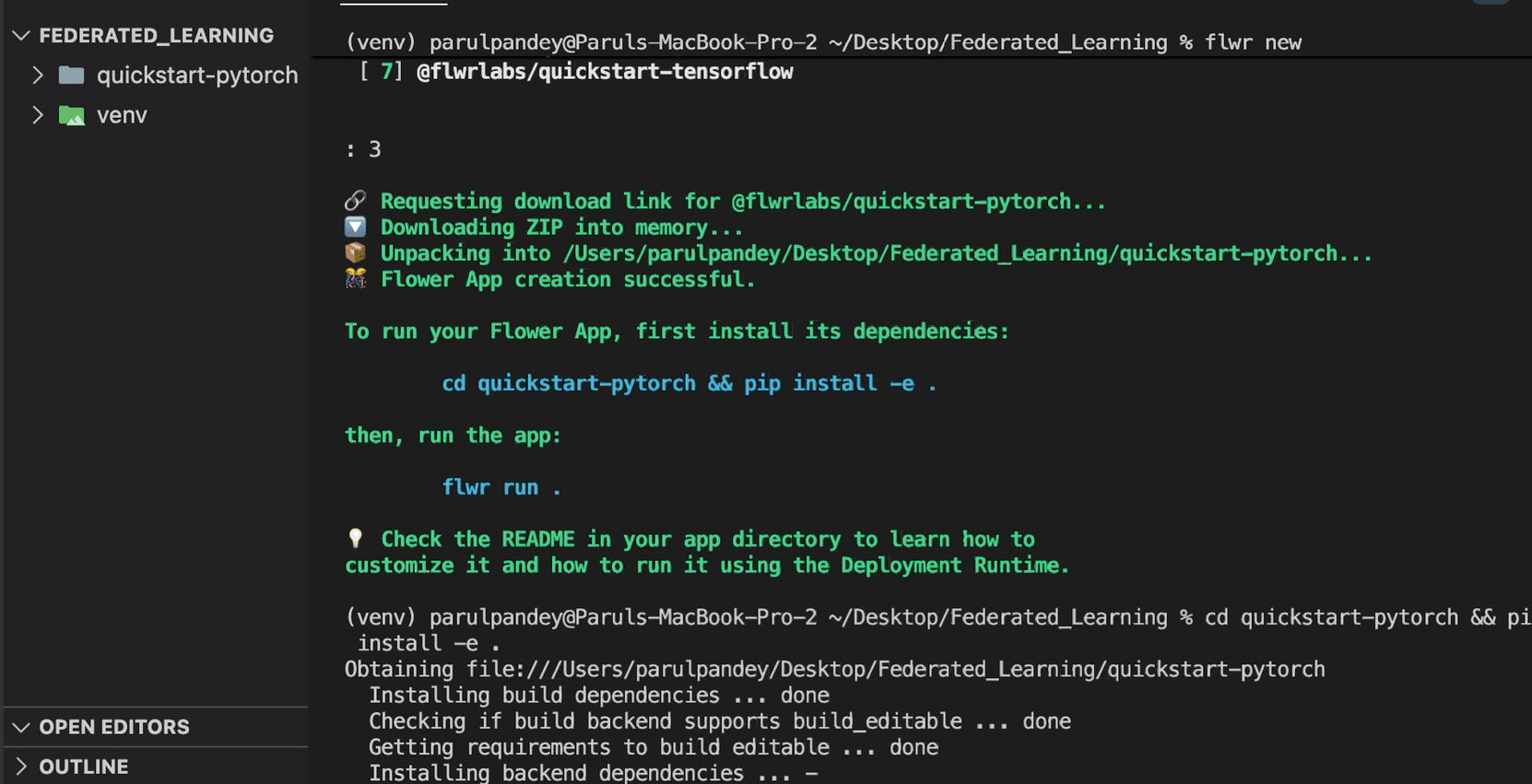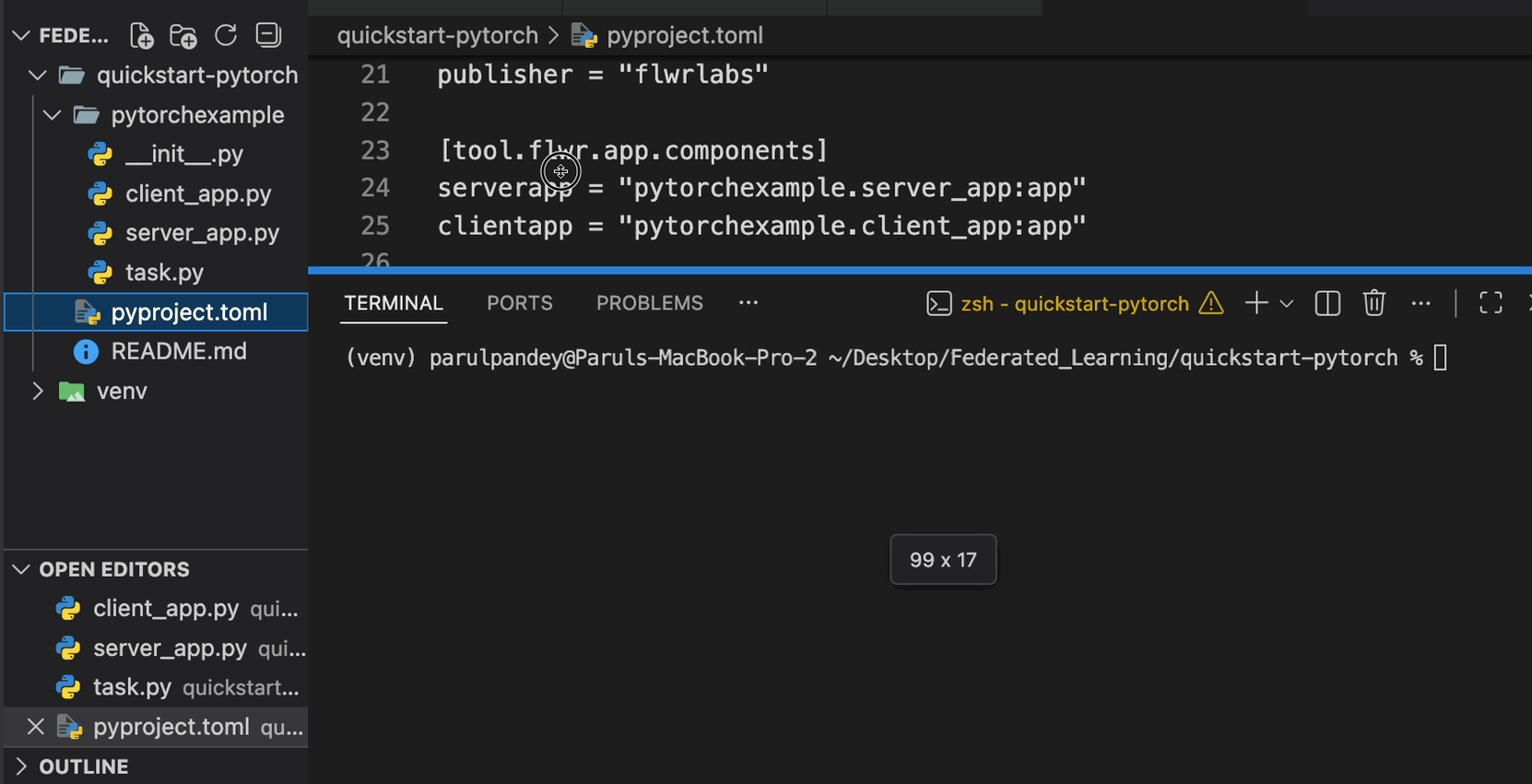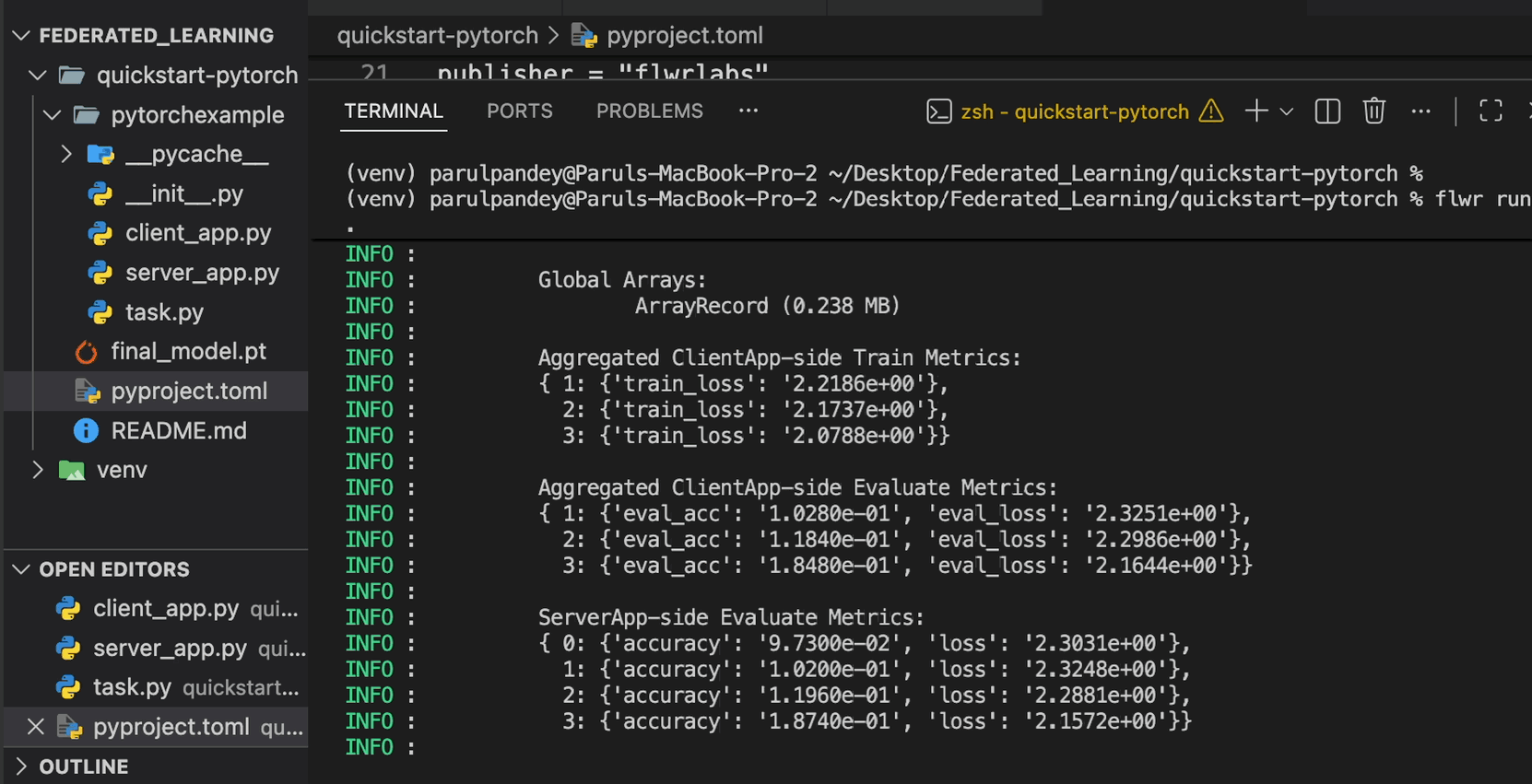
在MNIST联邦架构中,配置3轮服务端训练: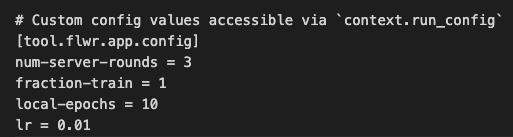
全局模型准确率达95.6%,缺失数值识别准确率跃升至93-97%:
混淆矩阵显示所有类别均有正确识别能力: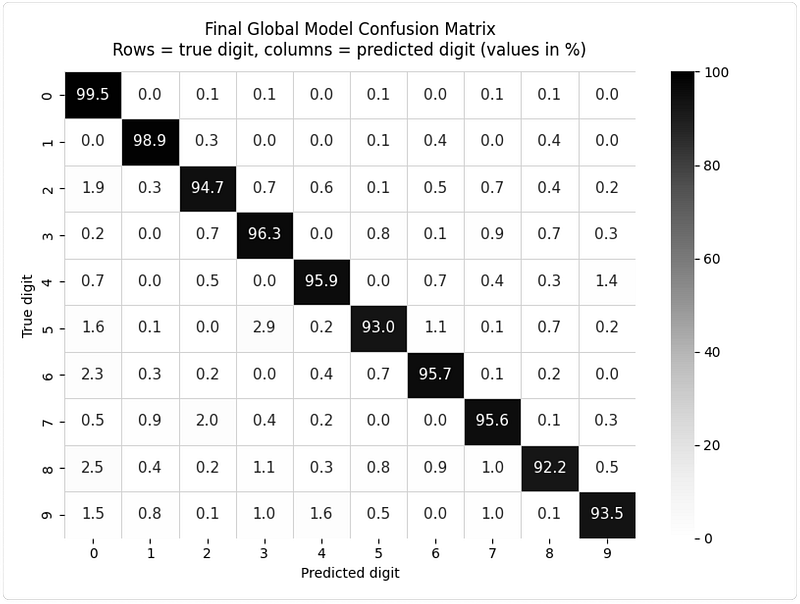
医疗场景应用前景
该技术可迁移至医院临床数据协作场景: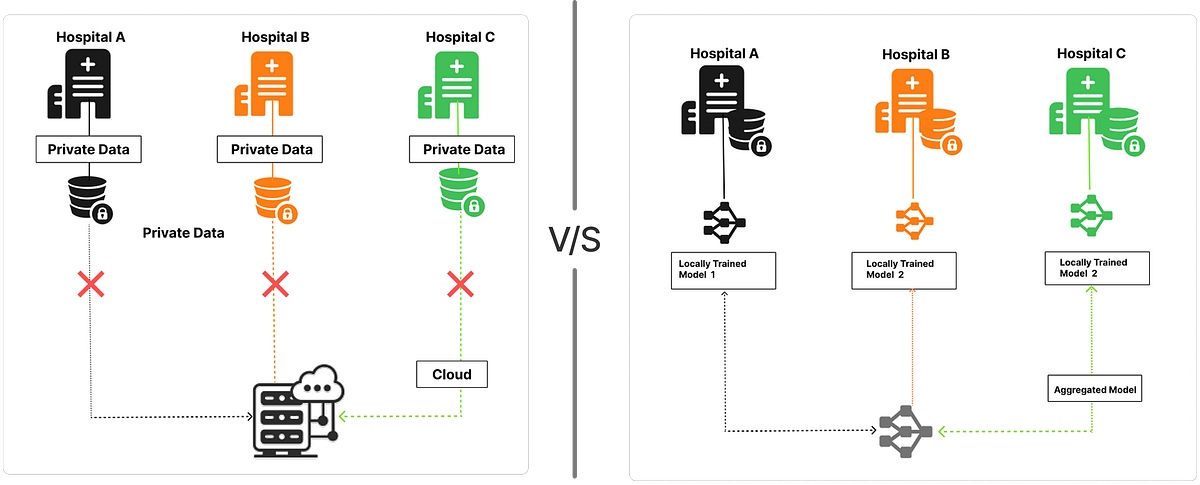
技术展望
尽管联邦学习本身实现数据最小化采集,模型参数更新仍存在隐私泄露风险,后续将专题探讨隐私增强技术方案。官方文档中的差分隐私与安全聚合模块为重要研究方向。




