

订阅我们的每日和每周新闻简报,获取有关行业领先人工智能报道的最新更新和独家内容。了解更多
人工智能开发就像开源软件的早期狂野西部时代——模型相互构建,从不同地方拼凑在一起,融合了不同的元素。
与开源软件一样,这在可见性和安全性方面也带来了问题:开发人员如何才能知道预构建模型的基础元素是否值得信赖、安全可靠?
为了更深入地了解人工智能模型的内部结构,软件供应链安全公司 Endor Labs 今天发布了针对人工智能模型的 Endor Labs 评分。这个新平台对目前在 Hugging Face 上可用的 90 多万个开源人工智能模型进行了评分,Hugging Face 是全球最受欢迎的人工智能中心之一。
“毫无疑问,我们正处于起步阶段,早期阶段,”Endor Labs 的创始工程师乔治·阿波斯托洛普洛斯告诉 VentureBeat。“模型的黑盒子是一个巨大的挑战;从互联网上下载二进制代码存在风险。”
Endor Labs 的新平台使用 50 个开箱即用的指标,根据安全性、活动性、质量和受欢迎程度对 Hugging Face 上的模型进行评分。开发人员无需深入了解特定模型——他们可以使用平台提出问题,例如“哪些模型可以对情绪进行分类?”“Meta 最受欢迎的模型有哪些?”或“什么是流行的语音模型?”
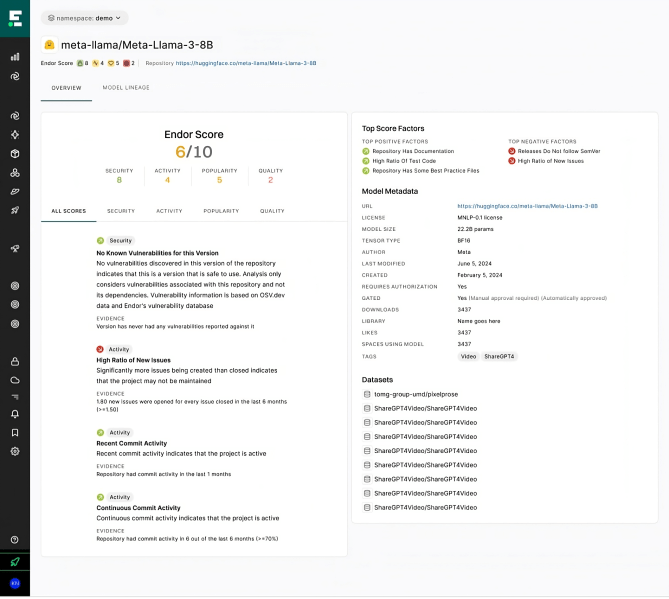 Courtesy Endor Labs.
Courtesy Endor Labs.
然后,该平台会告诉开发人员模型的受欢迎程度和安全性,以及模型最近的创建和更新时间。
阿波斯托洛普洛斯将人工智能模型中的安全性称为“复杂而有趣”。存在许多漏洞和风险,模型容易受到恶意代码注入、拼写错误和任何环节的被盗用户凭据的影响。
“随着这些技术的普及,攻击者将会无处不在,这只是时间问题,”阿波斯托洛普洛斯说。“攻击媒介如此之多,很难获得信心。可见性至关重要。”
Endor 专注于保护开源依赖项,根据 Hugging Face 数据和已知攻击文献开发了四个评分类别。该公司部署了大型语言模型来解析、组织和分析这些数据,其新平台会自动且持续地扫描模型更新或更改。
阿波斯托洛普洛斯表示,随着 Endor 收集更多数据,将考虑其他因素。该公司最终还将扩展到 Hugging Face 之外的其他平台,例如 OpenAI 等商业提供商。
“我们将讲述一个关于人工智能治理的更宏大的故事,随着越来越多的人开始部署人工智能,这变得越来越重要,”阿波斯托洛普洛斯说。
阿波斯托洛普洛斯指出,人工智能的发展与开源软件 (OSS) 的发展有很多相似之处。两者都拥有众多选择,以及众多风险。在 OSS 中,软件包可能会引入隐藏漏洞的间接依赖项。
同样,Hugging Face 上绝大多数模型都是基于 Llama 或其他开源选项。“这些人工智能模型几乎就是依赖项,”阿波斯托洛普洛斯说。
人工智能模型通常是在其他模型的基础上构建的,或者本质上是其他模型的扩展,开发人员会根据其特定用例对其进行微调。这创造了他所说的“复杂的依赖关系图”,既难以管理又难以保护。
“在最底层,五层深的地方,存在着这个基础模型,”阿波斯托洛普洛斯说。获得清晰度和透明度可能很困难,可用的数据可能很复杂,而且“非常痛苦”,让人难以阅读和理解。很难确定模型权重中究竟包含了什么,而且没有可靠的方法来确保模型是它声称的那样,值得信赖,如宣传的那样,并且不会产生有毒内容。
“基本的测试不是一件轻而易举的事,”阿波斯托洛普洛斯说。“现实情况是,信息非常少,而且非常零散。”
虽然下载开源软件很方便,但它也“极其危险”,因为恶意行为者可以轻松地破坏它,他说。
例如,模型权重的常见存储格式允许任意代码执行(或者当攻击者可以访问并运行他们想要的任何命令或代码时)。阿波斯托洛普洛斯解释说,对于基于 PyTorch、Tensorflow 和 Keras 等旧格式构建的模型来说,这尤其危险。此外,部署模型可能需要下载其他恶意或存在漏洞的代码(或者试图导入存在漏洞的依赖项)。而且,安装脚本或存储库(以及指向它们的链接)也可能是恶意的。
除了安全性之外,还存在许多许可障碍:与开源软件类似,模型受许可证的约束,但人工智能引入了新的复杂性,因为模型是在具有自身许可证的数据集上训练的。阿波斯托洛普洛斯强调,当今的组织必须了解模型使用的知识产权 (IP) 以及版权条款。
“一个重要的方面是这些大型语言模型与传统的开源依赖项的相似之处和不同之处,”他说。虽然两者都从外部来源获取数据,但大型语言模型更强大、更大,并且由二进制数据组成。
开源依赖项会“不断更新”,而人工智能模型“相当静态”——当它们更新时,“你很可能不会再碰它们,”阿波斯托洛普洛斯说。
“大型语言模型只是一堆数字,”他说。“它们更难评估。”




