大型语言模型的自我纠正:Google DeepMind 的 SCoRe 技术
大型语言模型 (LLM) 在处理复杂任务方面日益强大,但它们并非每次都能在第一次尝试中给出正确答案。因此,人们越来越关注赋予 LLM 自我纠正的能力,即“自我校正”。然而,现有的自我校正方法存在局限性,其要求在现实世界中往往难以满足。
Google DeepMind 的研究人员在最新论文中提出了一种名为“通过强化学习进行自我校正 (SCoRe)”的新技术。SCoRe 利用仅由模型自身生成的数据,显著提升了 LLM 的自我校正能力。SCoRe 有望成为增强 LLM 鲁棒性和可靠性的宝贵工具,并为提升其推理和解决问题的能力开辟新的可能性。
“自我校正是人类思维中至关重要的能力,”Google DeepMind 的研究科学家 Aviral Kumar 表示,“人类通常会花更多时间思考,尝试多种想法,纠正错误,最终才能解决难题,而不是仅仅一次性地给出解决方案。我们希望 LLM 也能做到这一点。”
理想情况下,具有强大自我校正能力的 LLM 应该能够审查和改进自己的答案,直到得出正确的结果。这一点尤其重要,因为 LLM 通常拥有解决问题的内部知识,但在生成初始响应时却无法有效地利用这些知识。
“从基础机器学习的角度来看,我们不期望任何 LLM 能在零样本情况下仅凭其记忆解决难题(人类也无法做到这一点),因此我们希望 LLM 能进行更多思考计算,并自我纠正以解决难题,”Kumar 解释道。
以往赋予 LLM 自我校正能力的方法依赖于提示工程或专门针对自我校正进行微调模型。这些方法通常假设模型能够接收关于输出质量的外部反馈,或能够访问“预言机”来指导自我校正过程。
这些技术未能利用模型的内在自我校正能力。监督微调 (SFT) 方法,即训练模型来修正基础模型的错误,也存在局限性。它们通常需要来自人类标注者或更强大模型的预言机反馈,并且不依赖于模型自身的知识。一些 SFT 方法甚至需要在推理过程中使用多个模型来验证和改进答案,这使得它们难以部署和使用。
此外,DeepMind 的研究表明,虽然 SFT 方法可以改进模型的初始响应,但当模型需要在多个步骤中修改其答案时,它们的表现并不理想,而这在处理复杂问题时经常发生。
“训练结束时,模型可能已经学会如何修正基础模型的错误,但可能没有足够的识别自身错误的能力,”Kumar 指出。
SFT 的另一个挑战是它可能导致意想不到的行为,例如模型学会在第一次尝试中生成最佳答案,并在后续步骤中不再改变它,即使它是错误的。
“我们发现,经过 SFT 训练的模型的行为很大程度上会坍缩成这种‘直接’策略,而不是学习如何自我校正,”Kumar 说道。
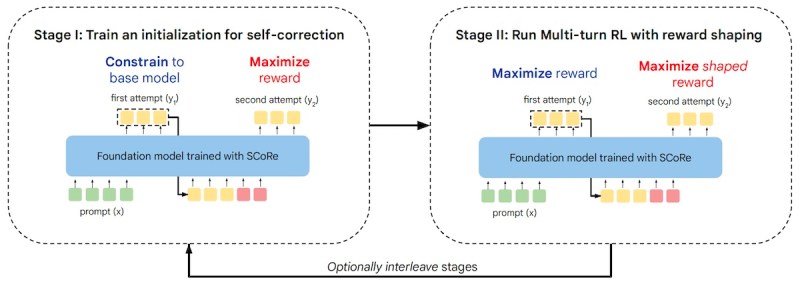
DeepMind SCoRe 框架(来源:arXiv)
为了克服以往方法的局限性,DeepMind 的研究人员转向了强化学习 (RL)。
“如今的 LLM 无法做到 [自我校正],这一点从以往评估自我校正能力的研究中可以明显看出。这是一个基本问题,”Kumar 表示,“LLM 并没有经过训练来回顾和反省自己的错误,它们经过训练的是在给定问题的情况下生成最佳响应。因此,我们开始构建自我校正方法。”
SCoRe 训练单个模型来生成响应并纠正自身的错误,而无需依赖外部反馈。重要的是,SCoRe 通过完全在模型自身生成的数据上训练模型来实现这一点,消除了对外部知识的需求。
以往尝试将 RL 用于自我校正的方法大多依赖于单轮交互,这可能导致不良结果,例如模型只关注最终答案,而忽略了指导自我校正的中间步骤。
“我们确实看到了……在经过训练以进行自我校正的 LLM 中出现的‘行为坍缩’。它学会了简单地忽略自我校正的指令,并从其记忆中生成最佳响应,在零样本情况下,没有学习如何自我校正,”Kumar 解释道。
为了防止行为坍缩,SCoRe 使用了具有正则化技术的两阶段训练过程。第一阶段用一个优化校正性能的过程来代替 SFT,同时确保模型的初始尝试保持接近基础模型的输出。
第二阶段采用多轮 RL 来优化初始和后续尝试的奖励,同时加入奖励奖励,鼓励模型从第一次到第二次尝试改进其响应。
“初始化和奖励奖励都确保模型不能简单地学会生成最佳的第一次尝试响应,然后只进行微小的编辑,”研究人员写道,“总的来说,SCoRe 能够从基础模型中提取知识,从而实现积极的自我校正。”
DeepMind 的研究人员将 SCoRe 与现有的使用自身生成数据进行自我校正训练的方法进行了比较。他们重点关注数学和编码任务,使用了 MATH、MBPP 和 HumanEval 等基准。
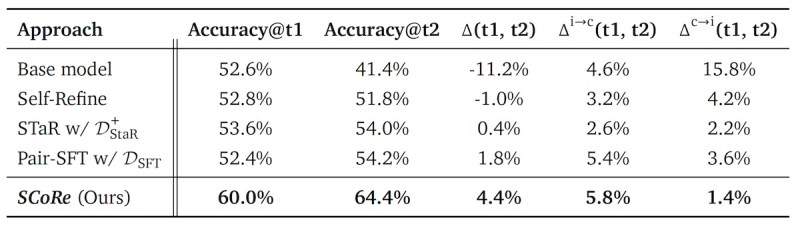
DeepMind SCoRe 在多步校正中优于其他自我校正方法。它还学会了在校正阶段避免切换正确的答案(来源:arXiv)
结果表明,SCoRe 显著提升了 Gemini 1.0 Pro 和 1.5 Flash 模型的自我校正能力。例如,与基础模型相比,SCoRe 在 MATH 基准测试中实现了 15.6% 的自我校正绝对增益,在 HumanEval 基准测试中实现了 9.1% 的增益,比其他自我校正方法高出几个百分点。
最显著的改进是模型从第一次到第二次尝试纠正错误的能力。SCoRe 还显著减少了模型错误地将正确答案更改为错误答案的实例,表明它学会了仅在必要时应用校正。
此外,SCoRe 与推理时间扩展策略(如自一致性)相结合时,证明了其高效性。通过将相同的推理预算分配到多个校正轮次,SCoRe 实现了进一步的性能提升。
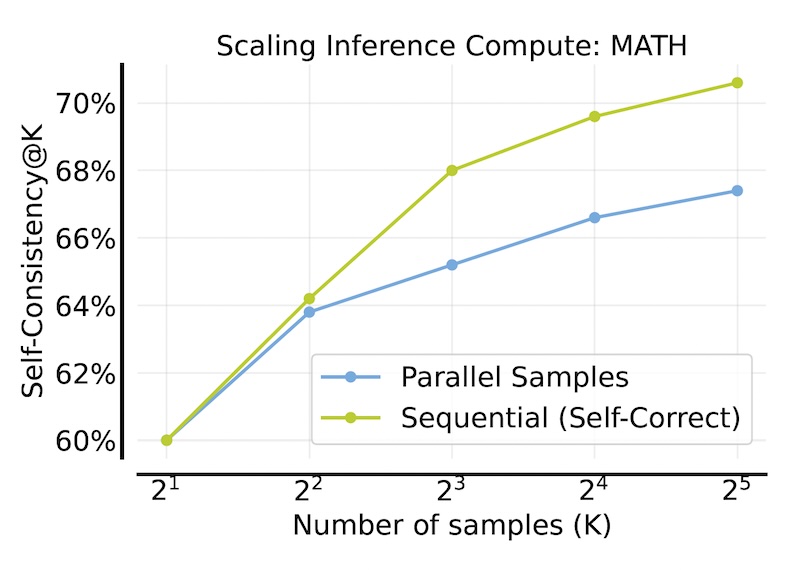
SCoRe(绿色线)使 LLM 能够更好地利用推理时间扩展技术(来源:arXiv)
虽然这篇论文主要关注编码和推理任务,但研究人员认为 SCoRe 也能为其他应用带来益处。
“你可以想象,教模型回顾它们可能存在安全风险的输出,并在向用户展示之前自行改进它们,”Kumar 说道。
研究人员认为,他们的工作对训练 LLM 具有更广泛的意义,并强调了教模型如何推理和自我纠正的重要性,而不是仅仅将输入映射到输出。