

模拟芯片的AI新纪元:Sageance能否颠覆算力格局?

在人工智能领域,算力一直是制约发展的关键因素。传统数字芯片在处理庞大模型时,面临着高能耗和高成本的挑战。而模拟芯片,凭借其独特的优势,被寄予厚望,有望成为下一代AI算力的突破口。
硅谷初创公司Sageance宣称,他们已经掌握了将模拟芯片的优势应用于大型生成式AI模型的技术。他们声称,其系统能够以Nvidia H100 GPU系统的十分之一的功耗,二十分之一的成本和二十分之一的空间运行Llama 2-70B大型语言模型。
Sageance的创始人兼首席执行官Vishal Sarin表示:“我的愿景是创造一种与现有AI技术截然不同的技术。”早在2018年公司成立之初,他就意识到“功耗将成为AI大规模应用的关键障碍……随着生成式AI的兴起,模型规模不断膨胀,这个问题变得更加严峻。”
模拟AI的优势在于它不需要移动数据,并利用基本的物理原理进行机器学习中最关键的数学运算。
这个数学问题是向量相乘并累加结果,称为乘累加。工程师们很早就意识到,电气工程的两个基本定律可以做到这一点,而且几乎是瞬间完成的。欧姆定律——电压乘以电导等于电流——如果将神经网络的“权重”参数作为电导,就可以实现乘法。基尔霍夫电流定律——进入和离开一个点的电流之和为零——意味着你可以通过将所有这些乘法连接到同一条线上轻松地将它们加起来。最后,在模拟AI中,神经网络参数不需要从内存移动到计算电路——通常比计算本身的能量成本更高——因为它们已经嵌入到计算电路中。
Sageance使用闪存单元作为电导值。通常用于数据存储的闪存单元是一个可以存储3或4位的单晶体管,但Sageance开发了算法,使嵌入其芯片的单元可以存储8位,这是LLM和其他所谓的Transformer模型的关键精度水平。Sarin表示,在单个晶体管中存储一个8位数字,而不是在典型的数字存储单元中存储48个晶体管,这在成本、面积和能耗方面都具有重要意义。他从事闪存多位存储研究已有30年。
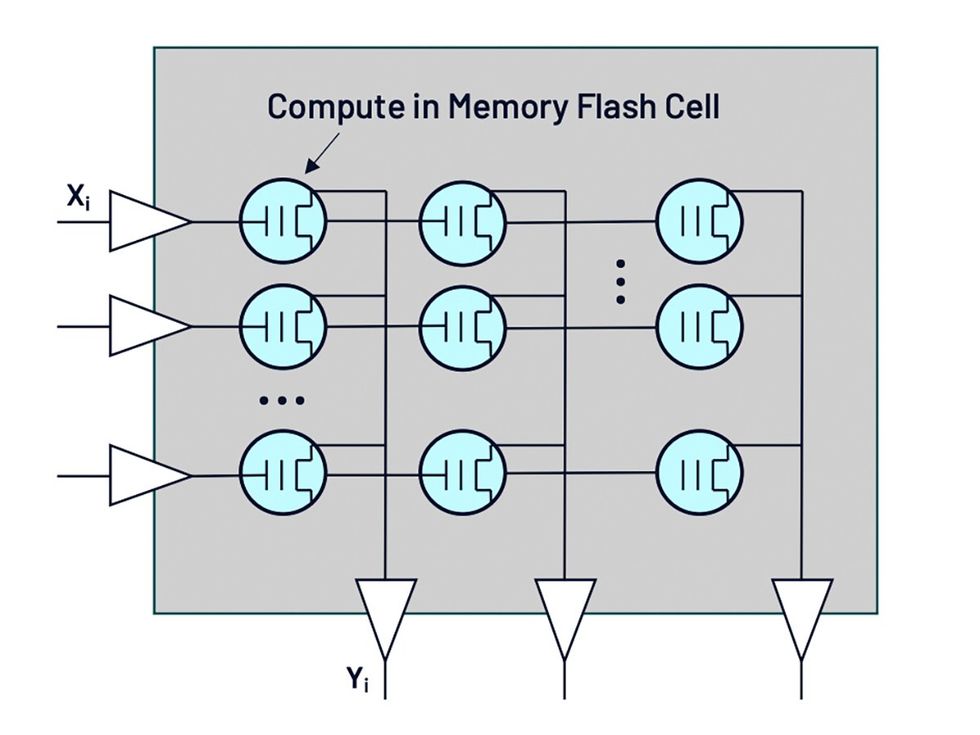
数字数据被转换为模拟电压[左]。这些电压实际上被闪存单元[蓝色]相乘,然后相加,最后被转换回数字数据[底部]。
模拟推理
此外,闪存单元在“深亚阈值”状态下运行,这意味着它们处于几乎不开启的状态,产生很少的电流。这在数字电路中是不可行的,因为它会使计算速度变得非常慢。但由于模拟计算是同时完成的,因此不会影响速度。
模拟AI的挑战
如果这一切听起来似曾相识,那就不足为奇了。早在2018年,就有三家初创公司致力于开发基于闪存的模拟AI。Syntiant最终放弃了模拟方法,转而采用数字方案,迄今已量产了六款芯片。Mythic和Anaflash则坚持了下来。其他公司,特别是IBM Research,开发了依赖于非易失性存储器(而非闪存)的芯片,例如相变存储器或阻变式RAM。
总的来说,模拟AI难以实现其潜力,尤其是在扩展到数据中心可能需要的规模时。其主要困难在于电导单元的自然变化;这意味着存储在两个不同单元中的相同数字会导致两个不同的电导。更糟糕的是,这些电导会随着时间的推移而漂移,并随着温度而变化。这种噪声会淹没代表结果的信号,并且噪声可能会在深度神经网络的多个层中逐层叠加。
Sarin解释说,Sageance的解决方案是在芯片上设置一组参考单元,并使用专有算法来校准其他单元并跟踪与温度相关的变化。
开发模拟AI的另一个令人沮丧的问题是,需要将乘累加过程的结果数字化,以便将其传递到神经网络的下一层,在那里它必须再次转换为模拟电压信号。每一步都需要模数转换器和数模转换器,它们会占用芯片面积并消耗能量。
Sarin表示,Sageance已经开发出两种电路的低功耗版本。由于电路需要提供非常窄的电压范围才能使闪存以深亚阈值模式运行,因此数模转换器的功耗需求得到了缓解。
系统和未来展望
Sageance的首款产品将于2025年推出,面向视觉系统,这比基于服务器的LLM要轻便得多。“这对我们来说是一个飞跃式产品,之后很快就会推出生成式AI,”Sarin说。
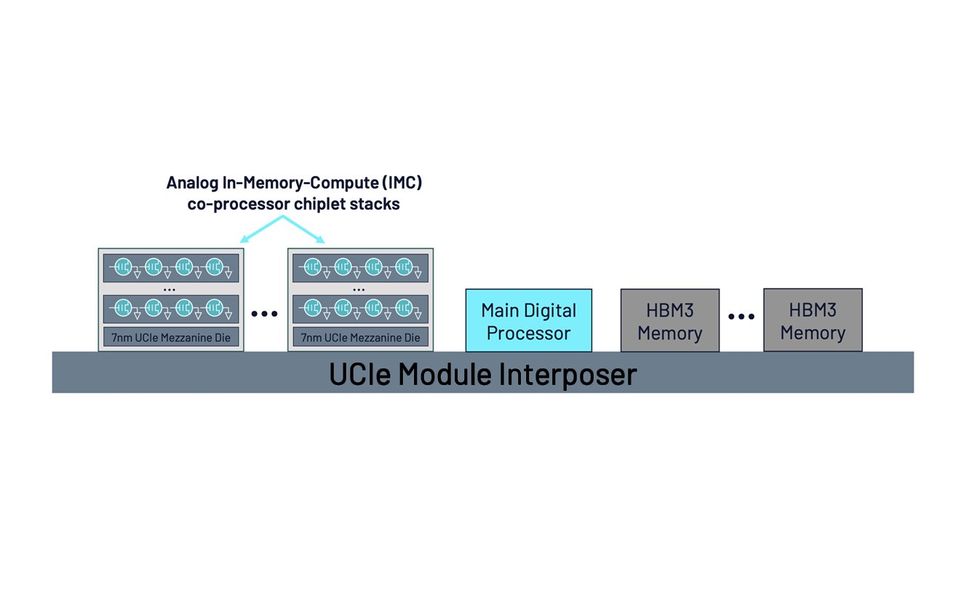
Sageance未来的系统将由3D堆叠的模拟芯片组成,这些芯片通过遵循通用芯片互连(UCIe)标准的互连器连接到处理器和内存。
模拟推理
生成式AI产品将主要通过在通信芯片之上垂直堆叠模拟AI芯片来扩展视觉芯片。这些堆栈将通过一个名为Delphi的单一封装连接到CPU芯片和高带宽内存DRAM。
Sageance声称,在模拟中,由Delphi组成的系统将以每秒666,000个令牌的速度运行Llama2-70B,消耗59千瓦,而基于Nvidia H100的系统则消耗624千瓦。





