

DeepSeek 推出全新推理型大语言模型 R1-Lite-Preview,性能媲美 OpenAI
DeepSeek,一家由中国量化对冲基金 High-Flyer Capital Management 孵化的 AI 公司,致力于发布高性能开源技术,近日推出了其最新的推理型大语言模型 (LLM) R1-Lite-Preview。目前,该模型仅通过 DeepSeek Chat,其基于网络的 AI 聊天机器人,提供独家访问。
DeepSeek 以其对开源 AI 生态系统的创新贡献而闻名,其新发布的模型旨在将高级推理能力带给公众,同时坚持其对可访问和透明 AI 的承诺。
尽管 R1-Lite-Preview 目前仅通过聊天应用程序提供,但其性能已引起广泛关注,在某些情况下甚至超过了 OpenAI 备受赞誉的 o1-preview 模型。
与 2024 年 9 月发布的 o1-preview 模型类似,DeepSeek-R1-Lite-Preview 展示了“思维链”推理,向用户展示其为响应查询和输入而进行的各种“思维”链或轨迹,通过解释其正在做什么以及为什么来记录过程。
虽然一些思维链/轨迹可能对人类来说看起来毫无意义甚至错误,但 DeepSeek-R1-Lite-Preview 总体上似乎非常准确,甚至可以回答让其他更老但功能强大的 AI 模型(如 GPT-4o 和 Claude 的 Anthropic 家族)感到困惑的“陷阱”问题,例如“单词 Strawberry 中有多少个字母 R?”和“哪个更大,9.11 还是 9.9?”请参见以下我使用 DeepSeek Chat 测试这些提示的截图:



DeepSeek-R1-Lite-Preview 旨在擅长需要逻辑推理、数学推理和实时解决问题的任务。
据 DeepSeek 称,该模型在 AIME(美国数学邀请赛)和 MATH 等既定基准测试中超越了 OpenAI o1-preview 水平的性能。
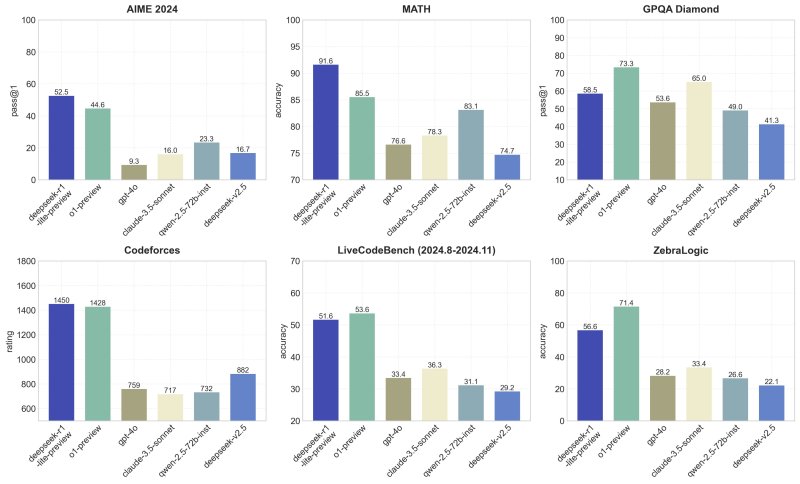 DeepSeek-R1-Lite-Preview 在 X 上发布的基准测试结果。
DeepSeek-R1-Lite-Preview 在 X 上发布的基准测试结果。
其推理能力通过其透明的思维过程得到增强,使用户能够逐步跟踪模型解决复杂挑战的过程。
DeepSeek 还发布了扩展数据,展示了当模型获得更多时间或“思维令牌”来解决问题时,其准确性稳步提高。性能图表突出了其在 AIME 等基准测试中随着思维深度的增加而获得更高分数的能力。
DeepSeek-R1-Lite-Preview 在关键基准测试中表现出色。
该公司发布的结果突出了其处理各种任务的能力,从复杂的数学到基于逻辑的场景,在 GPQA 和 Codeforces 等推理基准测试中获得了与顶级模型相媲美的性能分数。
其推理过程的透明度进一步使其脱颖而出。用户可以实时观察模型的逻辑步骤,增加了许多专有 AI 系统所缺乏的责任感和信任感。
然而,DeepSeek 尚未发布完整的代码以供独立第三方分析或基准测试,也尚未通过 API 提供 DeepSeek-R1-Lite-Preview,这将允许进行相同类型的独立测试。
此外,该公司尚未发布博客文章或技术论文来解释 DeepSeek-R1-Lite-Preview 的训练或架构方式,这留下了许多关于其底层起源的疑问。
R1-Lite-Preview 现在可以通过 DeepSeek Chat(chat.deepseek.com)访问。虽然该模型对公众免费使用,但其高级“深度思考”模式每天限制 50 条消息,为用户提供了充分的机会体验其功能。
展望未来,DeepSeek 计划根据该公司在 X 上的帖子发布其 R1 系列模型和相关 API 的开源版本。
此举符合该公司支持开源 AI 社区的历史。
其之前的版本 DeepSeek-V2.5 因将通用语言处理和高级编码能力相结合而获得了赞誉,使其成为当时最强大的开源 AI 模型之一。
DeepSeek 正在继续其在开源 AI 领域突破界限的传统。早期的模型,如 DeepSeek-V2.5 和 DeepSeek Coder,在语言和编码任务中展示了令人印象深刻的能力,基准测试将其定位为该领域的领导者。
R1-Lite-Preview 的发布增加了一个新的维度,专注于透明的推理和可扩展性。
随着企业和研究人员探索推理密集型 AI 的应用,DeepSeek 对开放性的承诺确保其模型仍然是开发和创新的重要资源。
通过将高性能、透明操作和开源可访问性相结合,DeepSeek 不仅在推动 AI 发展,而且正在重塑 AI 的共享和使用方式。
R1-Lite-Preview 现已开放公众测试。开源模型和 API 预计将陆续发布,进一步巩固 DeepSeek 作为可访问、先进 AI 技术领导者的地位。





