

2025 年人工智能展望:机遇与挑战并存
2024 年即将结束,回首这一年,人工智能取得了令人瞩目的突破性进展。站在新年的起点,展望 2025 年,人工智能将如何继续演进,为企业带来哪些机遇和挑战?
过去一年,大型语言模型(LLM)的推理成本持续下降。以 OpenAI 的旗舰模型为例,其每百万个词元的成本在过去两年中下降了 200 多倍。这一趋势主要得益于竞争加剧和硬件技术的进步。
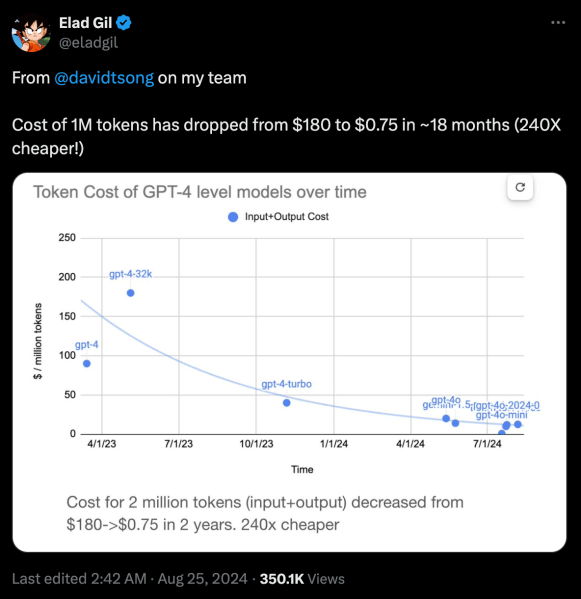
企业应该抓住这一机遇,积极尝试最先进的 LLM,并构建基于它们的应用原型。随着模型价格的持续下降,这些应用将很快实现规模化。同时,模型的能力也在不断提升,这意味着企业可以用更低的成本实现更多功能。
OpenAI 发布的 o1 模型引发了 LLM 领域的新一轮创新浪潮。o1 模型能够进行更长时间的思考,并对答案进行审查,这使得它能够解决以前无法通过单次推理解决的推理问题。尽管 OpenAI 尚未公开 o1 的细节,但其强大的能力已经引发了人工智能领域的竞赛。目前,许多开源模型已经复制了 o1 的推理能力,并将这种范式扩展到新的领域,例如回答开放式问题。
o1 类模型(有时被称为大型推理模型,LRM)的进步将对未来产生两方面的重要影响。首先,由于 LRM 需要生成大量的词元来回答问题,硬件公司将更有动力开发具有更高词元吞吐量的专用 AI 加速器。其次,LRM 可以帮助解决下一代语言模型面临的一个重要瓶颈:高质量的训练数据。据报道,OpenAI 正在使用 o1 生成其下一代模型的训练样本。我们也可以期待 LRM 帮助催生新一代专门针对特定任务的小型模型,这些模型将使用合成数据进行训练。
企业应该将时间和预算投入到探索 LRM 的应用潜力中。他们应该不断测试 LLM 的极限,并思考如果下一代模型克服了这些限制,哪些应用将成为可能。结合推理成本的持续下降,LRM 将在未来一年解锁许多新的应用。
Transformer 的内存和计算瓶颈是 LLM 中使用的主要深度学习架构,这催生了具有线性复杂度的替代模型领域。其中最受欢迎的架构是状态空间模型 (SSM),它在过去一年中取得了长足的进步。其他有前景的模型包括液体神经网络 (LNN),它使用新的数学方程,用更少的计算周期和人工神经元实现更多功能。
在过去一年中,研究人员和 AI 实验室发布了纯 SSM 模型以及结合了 Transformer 和线性模型优势的混合模型。尽管这些模型尚未达到最先进的基于 Transformer 模型的水平,但它们正在快速赶超,并且已经比 Transformer 模型快得多,效率也高得多。如果该领域的进展持续下去,许多更简单的 LLM 应用可以被卸载到这些模型上,并在边缘设备或本地服务器上运行,企业可以在不将数据发送给第三方的情况下使用定制数据。
LLM 的扩展规律不断发展。2020 年 GPT-3 的发布证明,扩展模型规模将继续带来令人印象深刻的结果,并使模型能够执行它们没有明确训练的任务。2022 年,DeepMind 发布了 Chinchilla 论文,它为数据扩展规律设定了新的方向。Chinchilla 证明,通过在比模型参数数量大几倍的巨大数据集上训练模型,可以继续获得改进。这一发展使小型模型能够与拥有数百亿参数的领先模型竞争。
今天,人们担心这两种扩展规律都接近其极限。有报道称,领先的实验室在训练更大模型方面正在经历收益递减。与此同时,训练数据集已经增长到数万亿个词元,获取高质量数据变得越来越困难和昂贵。
与此同时,LRM 正在提供一个新的方向:推理时间扩展。在模型和数据集规模失效的情况下,我们可以通过让模型运行更多推理周期并自行纠正错误来开拓新的领域。
当我们进入 2025 年,人工智能领域将继续以意想不到的方式发展,新的架构、推理能力和经济模型将重塑可能实现的目标。对于愿意尝试和适应的企业来说,这些趋势不仅代表着技术进步,而且代表着我们如何利用人工智能解决现实世界问题的根本转变。




