检索增强生成(RAG)一直是生成式AI最早且最成功的应用之一。然而,目前很少有聊天机器人能在提供文本答案的同时,从源文档中返回图像、表格和图表。
本文将深入探讨构建一个可靠、真正的多模态RAG系统为何如此困难,特别是对于包含密集文本、公式、表格和图表的复杂文档(如研究论文和企业报告)。
此外,本文还提出了一种改进的多模态RAG流水线方法,旨在为这些文档类型提供一致、高质量的多模态结果。
数据集与设置
为说明这一点,本文构建了一个小型多模态知识库,使用了以下文档:
使用的语言模型是GPT-4o,嵌入模型则采用了text-embedding-3-small。
标准多模态RAG架构
理论上,一个多模态RAG机器人应具备以下功能:
- 接受文本和图像查询。
- 返回文本和图像响应。
- 从文本和图像源中检索上下文。
典型的流水线通常如下所示:
- 数据摄取
- 解析与分块: 将文档分割成文本片段并提取图像。
- 图像摘要: 使用大型语言模型(LLM)为每张图像生成标题或摘要。
- 多向量嵌入: 为文本块、图像摘要以及可选的原始图像特征(例如,使用CLIP)创建嵌入。
2. 索引构建
- 将嵌入和元数据存储在向量数据库中。
3. 信息检索
- 针对用户查询,执行相似性搜索,范围包括:
- 文本嵌入(用于文本匹配)
- 图像摘要嵌入(用于图像相关性)
4. 响应生成
- 使用多模态LLM综合利用检索到的文本和图像来生成最终响应。
内在假设的挑战
这种标准方法假设,从图像内容生成的标题或摘要总是包含足够的上下文,足以关联文档中出现的文本或主题,使得该图像成为一个合适的响应。
然而,在实际文档中,情况往往并非如此。
示例:企业报告中的上下文丢失
以数据集中的“金融服务营销策略”(数据集中的第3份报告)为例。其执行摘要中包含两张外观相似的表格,展示了营运资金需求——一张针对初级生产者(农民),另一张针对加工商。它们分别是:

初级生产者营运资金表

加工商营运资金表
GPT-4o为第一张表格生成了以下描述:
“该表格概述了农业企业各种营运资金融资方案,包括其目的以及在不同情况下的可用性”
为第二张表格生成了以下描述:
“该表格概述了营运资金融资方案,详细说明了其目的以及在不同业务场景(特别是出口商和库存采购商)中的潜在适用性”
两者单独看似乎都很好——但都没有捕捉到区分生产者和加工商的关键上下文。
这意味着当查询专门针对生产者或加工商时,这些表格将被错误检索。在资本支出、融资机会等其他表格中,也存在相同的问题。
对于VectorPainter论文,其中图3展示了VectorPainter流水线,GPT-4o生成的标题是“概述了用于基于笔画的风格提取和带有笔画级约束的风格化SVG合成的提议框架”,但遗漏了它代表了论文核心主题“VectorPainter”这一事实。
而对于CLIP微调论文第3.3节中定义的视觉语言相似性蒸馏损失公式,生成的标题是“代表变分逻辑分布(VLD)损失的方程,定义为预测和目标逻辑分布在批次输入上的Kullback–Leibler(KL)散度之和”,其中缺少了视觉和语言关联的上下文。
值得注意的是,在研究论文中,图表通常包含作者提供的标题,但在提取过程中,这些标题并未作为图像的一部分被提取,而是作为文本的一部分。此外,标题的位置有时在图上方,有时在图下方。而对于营销策略报告,嵌入的表格和其他图像甚至没有附带描述性的标题。
上述情况表明,实际文档并未遵循任何标准化的文本、图像、表格和标题格式,这使得将上下文与图表关联起来变得十分困难。
全新改进的多模态RAG流水线
为解决这一问题,本方法进行了两项关键改进。
1. 上下文感知图像摘要
不再要求LLM直接总结图像,而是提取图像前后紧邻的文本——每个方向最多200个字符。
通过这种方式,图像标题将包含:
- 作者提供的标题(如果有)
- 赋予图像意义的周围叙述性文本
即使文档缺乏正式标题,这也提供了一个上下文准确的摘要。
2. 基于文本响应的生成时图像选择
在检索阶段,本方法不直接将用户查询与图像标题进行匹配。这是因为用户查询通常太短,无法为图像检索提供足够的上下文(例如:“什么是…?”)。
相反,流程如下:
- 首先,使用检索到的最佳文本块作为上下文,生成文本响应。
- 然后,根据生成的文本响应,与图像标题进行匹配,选择最相关的两张图像。
这确保了最终图像是与实际响应相关,而非仅仅与查询相关联而选出的。
以下是抽取到嵌入流水线的示意图:

抽取到嵌入流水线
检索与响应生成的流水线如下:
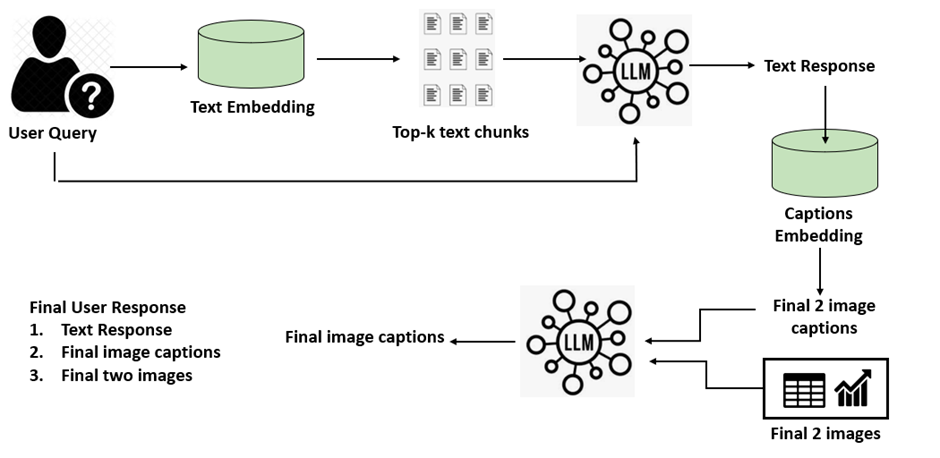
检索与响应生成流水线
实现细节
步骤1:提取文本和图像
使用Adobe PDF Extract API解析PDF文件,输出到:
- 包含.png文件的figures/和tables/文件夹
- 一个包含位置、文本和文件路径的structuredData.json文件
研究发现,该API在提取公式和图表方面比PyMuPDF等库更为可靠,尤其对于复杂文档。
步骤2:创建文本文件
将JSON文件中所有文本元素拼接起来,创建原始文本语料库:
# Extract text, sorted by Page and vertical order (Bounds[1])
elements = data.get("elements", [])
# Concatenate text
all_text = []
for el in elements:
if "Text" in el:
all_text.append(el["Text"].strip())
final_text = "
".join(all_text)
步骤3:构建图像标题:遍历structuredData.json的每个元素,检查元素文件路径是否以.png结尾。从文档的figures和tables文件夹加载文件,然后使用LLM对图像进行质量检查。这是必要的,因为提取过程中可能会发现一些难以辨认、过小、页眉页脚、公司标志等图像,这些需要从用户响应中排除。
请注意,此处并非要求LLM解释图像;只是判断其是否清晰且足够相关,可以包含在数据库中。LLM的提示词如下:
Analyse the given image for quality, clarity, size etc. Is it a good quality image that can be used for further processing ? The images that we consider good quality are tables of facts and figures, scientific images, formulae, everyday objects and scenes etc. Images of poor quality would be any company logo or any image that is illegible, small, faint and in general would not look good in a response to a user query.
Answer with a simple Good or Poor. Do not be verbose
接下来,创建图像摘要。为此,在structuredData.json中,查找.png元素之前和之后的元素,并在每个方向收集最多200个字符,总计400个字符。这构成了图像的标题或摘要。代码片段如下:
# Collect before
j = i - 1
while j >= 0 and len(text_before) < 200:
if "Text" in elements[j] and not ("Table" in elements[j]["Path"] or "Figure" in elements[j]["Path"]):
text_before = elements[j]["Text"].strip() + " " + text_before
j -= 1
text_before = text_before[-200:]
# Collect after
k = i + 1
while k < len(elements) and len(text_after) < 200:
if "Text" in elements[k]:
text_after += " " + elements[k]["Text"].strip()
k += 1
text_after = text_after[:200]
对数据库中每个文档的每个图表都执行此操作,并将图像标题作为元数据存储。在此案例中,图像描述作为image_captions.json文件存储。
这一简单的改变带来了巨大的差异——生成的标题包含了有意义的上下文。例如,从营销策略报告中获取的两个营运资金表的标题如下。请注意,上下文现在已清晰区分,并包含了农民和加工商。
"caption": "o farmers for their capital expenditure needs as well as for their working capital needs. The table below shows the different products that would be relevant for the small, medium, and large farmers. Working Capital Input Financing For purchase of farm inputs and labour Yes Yes Yes Contracted Crop Loan* For purchase of inputs for farmers contracted by reputable buyers Yes Yes Yes Structured Loan"``"caption": "producers and their buyers b) Potential Loan products at the processing level At the processing level, the products that would be relevant to the small scale and the medium_large processors include Working Capital Invoice discounting_ Factoring Financing working capital requirements by use of accounts receivable as collateral for a loan Maybe Yes Warehouse receipt-financing Financing working ca"
步骤4:文本分块并生成嵌入
将文档的文本文件分割成1000个字符的块,使用_langchain_中的RecursiveCharacterTextSplitter,并进行存储。为文本块和图像标题创建嵌入,并将其归一化后存储为_faiss_索引。
步骤5:上下文检索与响应生成
匹配用户查询,并检索前5个文本块作为上下文。然后,使用这些检索到的块和用户查询,通过LLM获取文本响应。
下一步,获取生成的文本响应,并找到与该响应最接近的2张图像(基于标题嵌入)。这与传统的将用户查询与图像嵌入匹配的方法不同,并能提供更好的结果。
还有一个最终步骤。由于图像标题是基于文档中图像周围的400个字符生成的,可能无法形成一个逻辑且简洁的显示标题。因此,对于最终选定的2张图像,会要求LLM结合图像标题和图像本身,创建一个简短的、可用于最终响应显示的标题。
以下是上述逻辑的代码:
# Retrieve context
result = retrieve_context_with_images_from_chunks(
user_input,
content_chunks_json_path,
faiss_index_path,
top_k=5,
text_only_flag= True
)
text_results = result.get("top_chunks", [])
# Construct prompts
payload_1 = construct_prompt_text_only (user_input, text_results)
# Collect responses (synchronously for tool)
assistant_text, caption_text = "", ""
for chunk in call_gpt_stream(payload_1):
assistant_text += chunk
lst_final_images = retrieve_top_images (assistant_text, caption_faiss_index_path, captions_json_path, top_n=2)
if len(lst_final_images) > 0:
payload = construct_img_caption (lst_final_images)
for chunk in call_gpt_stream(payload):
caption_text += chunk
response = {
"answer": assistant_text + ("
" + caption_text if caption_text else ""),
"images": [x['image_name'] for x in lst_final_images],
}
return response
测试结果
现在运行本文开头提到的查询,以检查检索到的图像是否与用户查询相关。为简化起见,此处仅打印图像及其显示的标题,不包含文本响应。
查询1:初级生产者的贷款和营运资金需求是什么?
图1:中小型和大型农民的营运资金融资方案概述。
图2:中大型农民的资本支出融资方案。

查询1的图像结果
查询2:加工商的贷款和营运资金需求是什么?
图1:中小型和中大型加工商的营运资金贷款产品概述。
图2:加工层面机械采购和业务扩张的资本支出贷款产品。

查询2的图像结果
查询3:什么是视觉语言蒸馏?
图1:用于将预训练CLIP模型的模态一致性转移到微调模型的视觉-语言相似性蒸馏损失公式。
图2:结合了蒸馏损失、监督对比损失和视觉-语言相似性蒸馏损失以及平衡超参数的最终目标函数。

查询3的公式检索结果
查询4:什么是VectorPainter流水线?
图1:笔画风格提取和SVG合成过程概述,突出显示了笔画矢量化、风格保持损失和基于文本提示的生成。
图2:各种栅格和矢量格式间风格迁移方法的比较,展示了所提出方法在保持风格一致性方面的有效性。
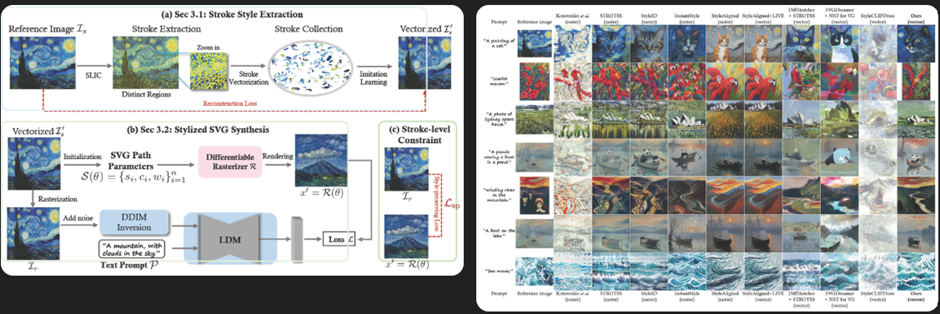
查询4的图像检索结果
结论
这一增强型流水线展示了上下文感知图像摘要和基于文本响应的图像选择如何显著提高多模态检索的准确性。
该方法能够生成丰富、多模态的答案,以连贯的方式结合文本和视觉信息——这对于研究助手、文档智能系统和AI驱动的知识机器人至关重要。