为什么你的XGBoost模型,永远在追赶未来?
洞察· 原作者:AccessPath 研究院· 8 分钟阅读0 阅读
从Kaggle竞赛到大厂推荐系统,XGBoost等树模型已成标配。但它们存在一个致命的结构性缺陷:无法预测训练数据范围之外的未来。本文揭示了树模型无法外推的“天花板”,并指出真正的破局点不在于调参,而在于通过特征工程重塑问题本身,让模型学会预测“变化”而非“绝对值”。
一、被“神化”的XGBoost,也有阿喀琉斯之踵
在任何一个数据科学家的工具箱里,XGBoost、LightGBM 这类基于树的集成模型,几乎都是处理结构化数据的首选。从各大平台的Kaggle竞赛,到阿里、字节的推荐与广告系统,它们的身影无处不在,因其高效、精准而备受推崇。
我们习惯于讨论它们的参数调优、性能对比,却常常忽略一个根本性的问题:这些强大的模型,其底层架构决定了它们有一个与生俱来的“天花板”——它们无法预测自己“没见过”的未来。
更具体地说,一个树模型,无论多么复杂,其预测结果永远不会超过训练数据中目标值的最大值,也永远不会低于最小值。当业务处于高速增长或面临趋势性变化时,这个看似微小的限制,可能就是模型失效的根本原因。
二、从一棵树到一片森林:越来越聪明的“盒子划分器”
要理解这个“天花板”的来源,需要回到最基础的决策树。
决策树的本质,是一个简单粗暴的“盒子划分器”。它通过一系列“是/否”问题(例如“年龄是否大于30岁?”“月收入是否高于1万?”),不断地将数据空间切分成一个个矩形区域。最终,落在同一个“盒子”(即叶子节点)里的所有样本,都会被赋予相同的预测值——通常是这个盒子里所有训练样本的平均值。
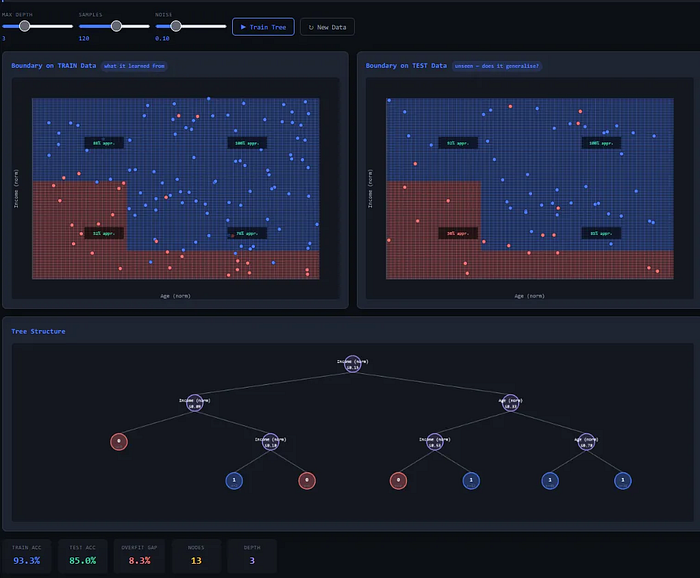
这种机制简单、直观,但也极其不稳定。一棵深度过大的决策树会疯狂地拟合训练数据中的噪声,在测试集上表现得一塌糊涂。
为了解决这个问题,两种更强大的范式应运而生:
-
随机森林(Random Forest):它的逻辑是“集体智慧”。通过构建数百棵各自独立的、略有不同的决策树(每棵树只看到部分数据和部分特征),然后让它们投票决定最终结果。这种方法有效地平滑了单个决策树粗糙、过拟合的决策边界,让模型变得更稳健。
-
梯度提升机(Gradient Boosting Machine, GBM):XGBoost和LightGBM都属于这个家族。它的逻辑是“迭代纠错”。它不像随机森林那样并行构建树,而是串行地、一棵接一棵地构建。第一棵树先做一个粗略的预测,第二棵树的任务是拟合第一棵树留下的“残差”(即预测错误),第三棵树再拟合前两棵树共同留下的残差……如此循环往复,每一棵新树都在为整个“模型天团”弥补短板。
无论是随机森林的“民主投票”,还是GBM的“精英迭代”,它们都只是在用更聪明的方式组合“盒子”。但核心机制从未改变:最终的预测值,依然是某个或某些“盒子”里训练样本的平均值。 这就注定了,模型无法创造一个训练集中从未出现过的新数值。
三、无法外推的“天花板”,正在拖累你的业务
这个结构性缺陷在处理趋势性数据时,会变得尤为致命。想象几个在中国市场常见的场景:
-
电商GMV预测:假设你在为拼多多的一个新兴业务线预测未来一个月的单日GMV。你的训练数据是过去半年的,其中单日GMV最高值为1000万。由于业务处于高速增长期,下个月的GMV很可能突破1200万。但无论你的XGBoost模型调得多好,它的预测值上限永远会被锁定在1000万。模型给出的曲线会呈现出令人困惑的“削顶”现象。
-
App用户增长预测:一个社交产品通过某个运营活动在抖音上爆火,DAU(日活跃用户)开始指数级增长。如果用历史数据训练一个GBM模型来预测未来一周的DAU,模型同样会“望顶兴叹”。它能捕捉到增长的“加速度”,但永远无法预测出一个它从未见过的DAU数值。它的预测永远是滞后的,像是在追赶现实的影子。
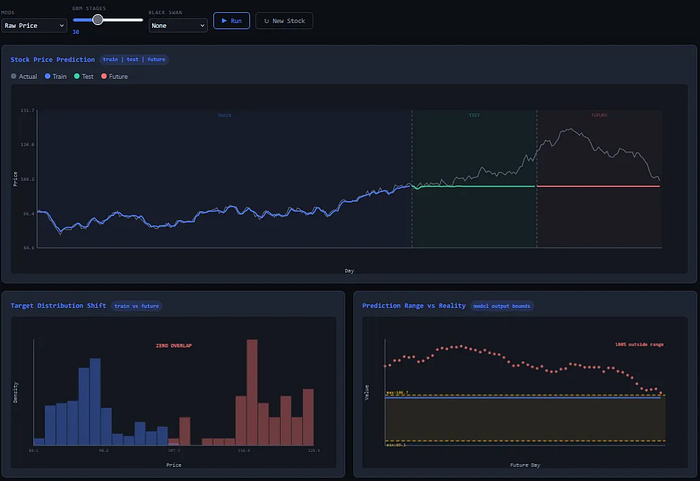
上图直观地展示了这个问题。模型在训练数据范围(蓝色区域)内表现完美,但在需要外推的未来(红色区域),预测变成了一条水平线——它只能输出自己见过的最大值。此时,模型没有“错”,它只是达到了其结构能力的极限。
四、破局之道:别再执着于调参,重塑你的问题
当模型撞上“外推天花板”时,继续增加树的数量、调低学习率,或是尝试更复杂的正则化参数,都已无济于事。真正的解决方案,在于后退一步,重新审视我们要求模型预测的到底是什么。
核心思路是:将预测一个非平稳的、有趋势的绝对值,转化为预测一个相对平稳的、无趋势的变化率或差值。
以前面的GMV预测为例:
- 错误的做法:
y = daily_GMV - 正确的做法:
y = daily_GMV_today / daily_GMV_yesterday(日环比增长率) 或者y = daily_GMV_today - daily_GMV_yesterday(日增长差值)
我们不再让模型直接预测“明天GMV是多少”,而是让它预测“明天GMV是今天的几倍”。增长率通常会在一个相对稳定的区间内波动(比如0.95到1.2之间),即使业务飞速增长,这个比率本身也是相对平稳的。这样一来,未来的目标值就落在了模型的“认知范围”之内。
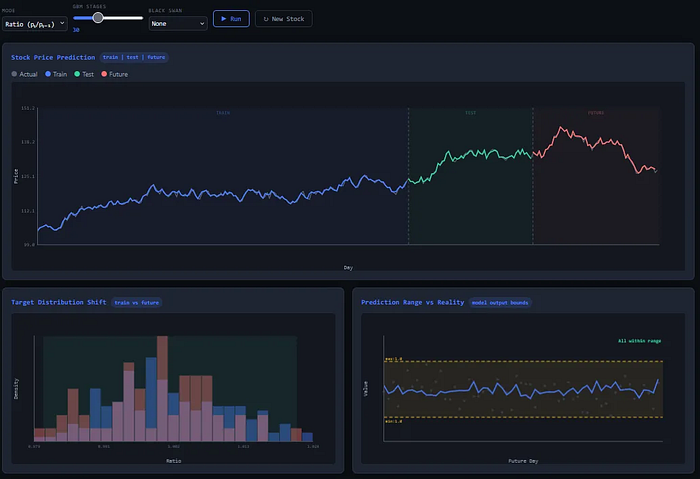
当我们用模型预测出明天的增长率为1.1后,再用今天的实际GMV乘以这个预测值,就能得到对明天GMV的最终预测。通过这种简单的特征工程,我们绕过了树模型的结构性缺陷,让它重新变得有效。
这背后体现了数据科学家工作的真正价值。它不仅仅是调用model.fit()和model.predict(),更是深刻理解模型的能力边界,并通过巧妙的问题转化,将复杂现实翻译成模型可以理解的“语言”。
五、结语:告别“模型神教”,回归问题本质
XGBoost、LightGBM、CatBoost无疑是伟大的工程杰作。LightGBM以其惊人的训练速度,在中国处理海量数据的互联网公司中备受青睐;CatBoost对类别特征的精妙处理,则解决了许多用户画像场景下的痛点。
但工具越是强大,使用者就越需要清醒。沉迷于自动化调参工具和模型性能的微小提升,可能会让我们忽视最根本的问题。树模型无法外推的特性,就是一个绝佳的例子,它提醒我们:任何模型都有其适用范围和局限性。
下一次,当你的模型效果不佳时,除了检查参数和特征,或许更应该问问自己:我提出的这个问题,对我的模型而言,公平吗?
想了解 AI 如何助力您的企业?
免费获取企业 AI 成熟度诊断报告,发现转型机会
//
24小时热榜


热门标签
关注公众号

扫码关注,获取最新 AI 资讯
免费获取 AI 落地指南
3 步完成企业诊断,获取专属转型建议
已有 200+ 企业完成诊断