Transformer自注意力机制详解:如何在Excel中理解文本的上下文建模
教程· 5 分钟阅读12 阅读
在结束这个机器学习系列之前,首先要诚挚感谢每一位关注、反馈和支持的读者,特别是Towards Data Sci […]
在结束这个机器学习系列之前,首先要诚挚感谢每一位关注、反馈和支持的读者,特别是Towards Data Science团队。
选择以Transformer模型作为收官之作并非偶然。Transformer不仅仅是一个时髦的名称,它构成了现代大语言模型的基石。
循环神经网络、长短时记忆网络和门控循环单元在序列建模史上扮演了关键角色。然而时至今日,现代大语言模型几乎完全建立在Transformer架构之上。
Transformer这个名称本身就标志着一个断裂。从命名角度看,作者本可以沿用“注意力神经网络”这类与“循环神经网络”或“卷积神经网络”保持一致的名称。但抛开命名不谈,Transformer带来的概念性转变完全配得上这个独特的称谓。
Transformer有多种应用方式。编码器架构常用于分类任务,解码器架构则用于下一个词元预测,即文本生成。
本文将聚焦于一个核心思想:注意力矩阵如何将输入词嵌入转化为更具语义信息的表示。
上一篇文章介绍了用于文本处理的一维卷积神经网络。该方法通过滑动窗口扫描句子,并在识别局部模式时产生响应。这种方法虽然强大,但存在明显局限:CNN仅关注局部信息。
现在,我们将向前迈进一步。
Transformer回答了一个根本不同的问题:如果每个词都能同时关注句子中的所有其他词,会发生什么?
1. 同一词语在不同语境中的差异
为了理解注意力机制的必要性,可以从一个简单的概念入手。
使用两个不同的输入句子,它们都包含“mouse”这个词,但语境截然不同。
第一个句子中,“mouse”与“cat”同时出现。第二个句子中,“mouse”则与“keyboard”相伴。

Transformer在Excel中的演示 – 所有图片由作者提供
在输入层面,有意为两个句子中的“mouse”使用相同的词嵌入。这一点很重要。在此阶段,模型并不知道词语所指的具体含义。
“mouse”的词嵌入同时包含:
- 强烈的动物属性成分
- 强烈的科技设备属性成分
这种歧义性是刻意设计的。没有上下文时,“mouse”可能指代动物或计算机设备。
其他词语则提供了更明确的信号。“Cat”具有强烈的动物属性。“Keyboard”具有强烈的科技属性。像“and”或“are”这类词主要承载语法信息。而“friends”和“useful”等词单独来看信息量较弱。
此时,输入词嵌入中没有任何信息能让模型判断“mouse”的正确含义。
下一节将逐步展示注意力矩阵如何完成这种转化。
2. 自注意力:上下文如何注入词嵌入
2.1 自注意力,而不仅仅是注意力
首先需要明确这里讨论的是哪种注意力机制。本节聚焦于自注意力。
自注意力意味着每个词会关注同一输入序列中的其他所有词。
在这个简化示例中,还做了一个教学上的选择:假设查询和键直接等于输入词嵌入。换言之,本节中没有为Q和K引入可学习的权重矩阵。
这是一个有意的简化,旨在让注意力机制本身成为焦点,而不引入额外参数。词语之间的相似度直接根据其词嵌入计算。
从概念上讲,这意味着:
Q = 输入
K = 输入
只有值向量会在后续用于将信息传播到输出。
在真实的Transformer模型中,Q、K和V都是通过可学习的线性投影得到的。这些投影增加了灵活性,但并未改变注意力机制的核心逻辑。此处展示的简化版本捕捉了核心思想。
以下是即将分解的完整示意图。

2.2 从输入词嵌入到原始注意力分数
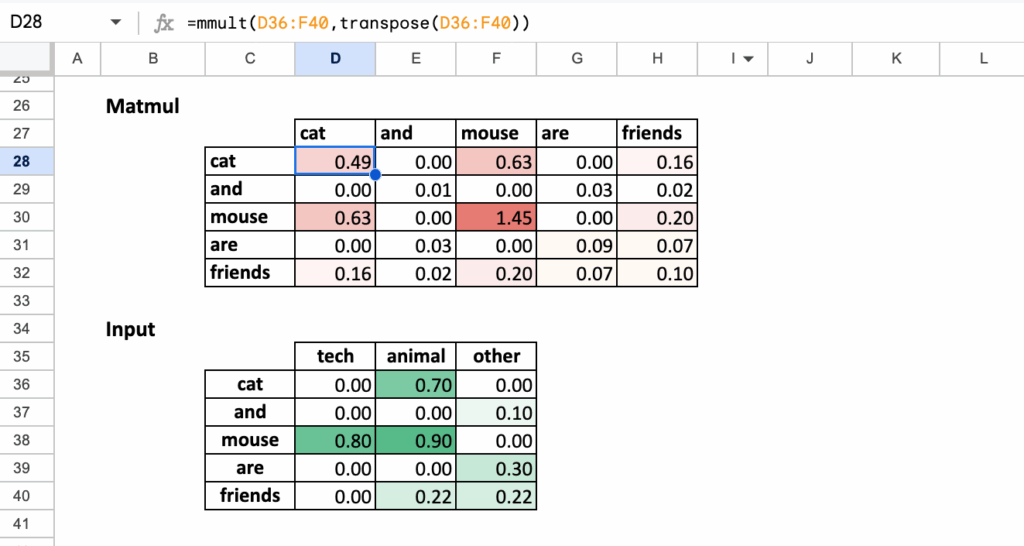
从输入词嵌入矩阵开始,其中每一行对应一个词,每一列对应一个语义维度。
第一步是计算每个词与其他所有词的相似度。这是通过计算查询和键的点积实现的。
由于本例中查询和键等于输入词嵌入,此步骤简化为计算输入向量之间的点积。
所有点积通过一次矩阵乘法完成:
分数 = 输入 × 输入ᵀ
该矩阵的每个单元格回答一个简单问题:给定它们的词嵌入,这两个词有多相似?
在此阶段,这些值是原始分数,还不是概率,也不能直接解释为权重。
2.3 缩放与归一化
原始点积值会随着词嵌入维度的增加而变大。为了将数值保持在稳定范围内,分数需要除以词嵌入维度的平方根进行缩放。
缩放后分数 = 分数 / √d
这个缩放步骤在概念上并不深奥,但实践上很重要。它防止下一步的softmax函数变得过于尖锐。

缩放完成后,逐行应用softmax函数。这将原始分数转化为和为1的正值。
结果就是注意力矩阵。
注意力就是所需的一切。
该矩阵的每一行描述了一个给定词对句子中其他每个词的关注程度。

2.4 解读注意力矩阵
注意力矩阵是自注意力的核心对象。
对于一个给定的词,其在注意力矩阵中的行回答了这个问题:在更新该词时,哪些其他词是重要的,重要程度如何?
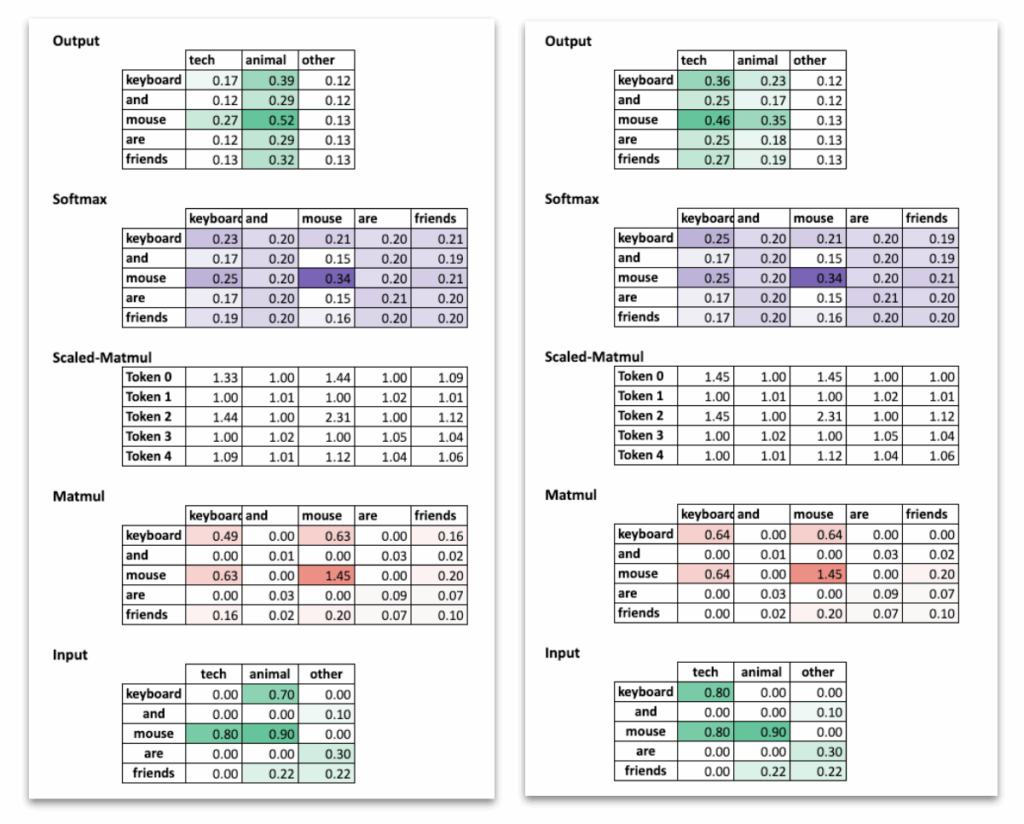
例如,对应“mouse”的行会给当前上下文中语义相关的词分配更高的权重。在包含“cat”和“friends”的句子中,“mouse”会更关注与动物相关的词。在包含“keyboard”和“useful”的句子中,则会更多地关注技术相关的词。
两种情况下机制是相同的,只是周围的词语改变了结果。
2.5 从注意力权重到输出词嵌入
注意力矩阵本身并非最终结果,它是一组权重。
为了生成输出词嵌入,需要将这些权重与值向量结合。
输出 = 注意力 × V
在这个简化示例中,值向量直接取自输入词嵌入。因此,每个输出词向量都是输入向量的加权平均,权重由注意力矩阵的对应行给出。
对于像“mouse”这样的词,这意味着其最终表示变成了:
- 其自身词嵌入
- 加上它最关注的词的词嵌入的混合
这正是上下文信息注入词表示的精确时刻。

自注意力处理结束后,词嵌入不再具有歧义。
“mouse”这个词在两个句子中不再具有相同的表示。其输出向量反映了上下文。在一种情况下,它表现得像动物;在另一种情况下,则像技术设备。
词嵌入表本身没有改变。改变的是词语间信息的组合方式。
这就是自注意力的核心思想,也是构建Transformer模型的基础。
现在比较左右两个例子:“cat and mouse”与“keyboard and mouse”,自注意力的效果变得清晰可见。
两种情况下,“mouse”的输入词嵌入是相同的。然而最终的表示却不同。在与“cat”的句子中,“mouse”的输出词嵌入由动物维度主导。在与“keyboard”的句子中,技术维度变得更为突出。词嵌入表没有任何改变。差异完全来自于注意力在混合值向量之前,如何在不同词之间重新分配权重。
这一对比凸显了自注意力的作用:它并非孤立地改变词语,而是通过考虑完整上下文来重塑它们的表示。
3. 学习如何混合信息

Transformers在Excel中的演示 – 所有图片由作者提供
3.1 为Q、K和V引入可学习权重
到目前为止,焦点一直放在自注意力机制本身。现在引入一个重要元素:可学习权重。
在真实的Transformer中,查询、键和值并非直接取自输入词嵌入,而是通过可学习的线性变换产生的。
对于每个词的嵌入,模型计算:
Q = 输入 × W_Q
K = 输入 × W_K
V = 输入 × W_V
这些权重矩阵在训练过程中学习得到。
在此阶段,通常保持相同的维度。输入词嵌入、Q、K、V以及输出词嵌入都具有相同数量的维度。这使得注意力的作用更容易理解:它在不改变表示所在空间的情况下修改表示。
从概念上讲,这些权重让模型能够决定:
- 词的哪些方面对于比较是重要的(Q和K)
- 词的哪些方面应该传播给其他词(V)

3.2 模型实际学习的内容
注意力机制本身是固定的。点积、缩放、softmax和矩阵乘法总是以相同的方式工作。模型实际学习的是这些投影。
通过调整Q和K的权重,模型学习如何为特定任务度量词之间的关系。通过调整V的权重,模型学习当注意力较高时应传播哪些信息。结构定义了信息如何流动,而权重定义了流动的是什么信息。
由于注意力矩阵依赖于Q和K,因此它是部分可解释的。可以检查哪些词关注哪些其他词,并观察通常与句法或语义对齐的模式。
当比较同一词在两个不同语境中的情况时,这一点变得很清楚。在两个例子中,“mouse”一词都以完全相同的输入词嵌入开始,其中包含动物和技术成分。就其本身而言,它是模糊的。
发生变化的不是词本身,而是它接收到的注意力。在包含“cat”和“friends”的句子中,注意力强调与动物相关的词。在包含“keyboard”和“useful”的句子中,注意力转向技术相关的词。机制和权重在两种情况下是相同的,但输出词嵌入却不同。差异完全来自于学习到的投影如何与周围上下文相互作用。
这正是注意力矩阵可解释的原因:它揭示了模型认为哪些关系对任务是有意义的。

3.3 有意改变维度
然而,没有任何规定强制要求Q、K和V必须与输入具有相同的维度。
特别是值投影,可以将词嵌入映射到不同大小的空间中。当这种情况发生时,输出词嵌入会继承值向量的维度。
这并非理论上的好奇。这正是真实模型中发生的情况,尤其是在多头注意力中。每个头在其自己的子空间中操作,通常维度较小,结果随后被连接成一个更大的表示。
因此,注意力可以做两件事:
- 跨词混合信息
- 重塑这些信息所在的空间
这解释了Transformer为何具有如此强大的扩展能力。
它们不依赖于固定特征。它们学习:
- 如何比较词语
- 如何路由信息
- 如何将意义投影到不同的空间

注意力矩阵控制信息流向何处。
学习到的投影控制流动的是什么信息以及如何表示它。
两者共同构成了现代语言模型背后的核心机制。
结论
这个系列围绕一个简单的理念构建:通过观察机器学习模型如何实际转换数据来理解它们。
Transformer是结束这段旅程的恰当方式。它们不依赖于固定规则或局部模式,而是依赖于序列中所有元素之间学习到的关系。通过注意力机制,它们将静态的词嵌入转化为上下文化的表示,这正是现代语言模型的基础。
再次感谢每一位关注这个系列、分享反馈和支持的读者,特别是Towards Data Science团队。
圣诞快乐 
所有Excel文件可通过此链接获取。早期支持者将获得最佳价值。
从第19天到第24天的文章中隐藏了折扣码。找到它们并选择你喜欢的那个。
想了解 AI 如何助力您的企业?
免费获取企业 AI 成熟度诊断报告,发现转型机会

//
24小时热榜








热门标签
关注公众号

扫码关注,获取最新 AI 资讯
免费获取 AI 落地指南
3 步完成企业诊断,获取专属转型建议
已有 200+ 企业完成诊断