机器学习模型揭秘:用Excel亲手实现,告别“黑箱”时代
技术· 5 分钟阅读2 阅读
如今,训练任何模型都变得异常简单。训练过程似乎总是通过同一个看似相同的fit方法完成。因此,人们习惯于认为训练 […]
如今,训练任何模型都变得异常简单。训练过程似乎总是通过同一个看似相同的fit方法完成。因此,人们习惯于认为训练任何模型都是相似且简单的。
随着自动机器学习(autoML)、网格搜索和生成式AI的出现,“训练”机器学习模型甚至可以通过简单的“提示”来完成。
但现实是,当我们调用model.fit时,每个模型背后的训练过程可能截然不同。每个模型处理数据的方式也大相径庭。
可以观察到两种几乎背道而驰的趋势:
- 一方面,人们训练、使用、操纵和预测的模型(例如生成式模型)变得越来越复杂。
- 另一方面,有时却难以解释简单模型(如线性回归、线性判别分类器)的原理,也无法手动复现其结果。
理解所使用的模型至关重要。而理解它们的最佳方式,就是亲手实现它们。有些人使用Python、R或其他编程语言来实现。但对于不编程的人来说,这仍然存在障碍。如今,理解人工智能对每个人都至关重要。此外,使用编程语言也可能将一些操作隐藏在已有的函数背后。由于函数被编码后运行,仅给出结果,这意味着每个操作步骤并未被清晰地展示出来,缺乏视觉化的解释。
因此,探索模型的最佳工具,被认为是Excel。其公式能够清晰地展示计算的每一步。
事实上,当拿到一个数据集时,大多数非程序员会首先在Excel中打开它以了解内容。这在商业世界中非常普遍。
即便是许多数据科学家,包括本文观点来源者,也会使用Excel快速浏览数据。在需要解释结果时,直接在Excel中展示往往是最有效的方式,尤其是在面对高管时。
在Excel中,一切都是可见的。不存在“黑箱”。可以看到每一个公式、每一个数字、每一次计算。
这极大地有助于理解模型的实际工作原理,没有捷径可言。
此外,无需安装任何额外软件。只需要一个电子表格。
接下来将发布一系列文章,介绍如何在Excel中理解和实现机器学习及深度学习模型。
作为“知识探索日历”系列,计划每天发布一篇文章。

由Gemini生成:“AI知识探索日历”
本系列适合谁?
对于正在学习的学生,这些文章提供了一个实践视角,旨在理解复杂公式的意义。
对于机器学习或AI开发者,有时可能没有深入学习过理论——但现在,无需复杂的代数、概率或统计知识,就可以揭开model.fit背后的黑箱。因为对于所有模型,虽然都调用model.fit,但实际上,这些模型可能千差万别。
这也适合那些可能不具备全部技术背景的管理者,Excel将为他们提供模型背后所有直观的概念。因此,结合业务专长,可以更好地判断机器学习是否真的必要,以及哪种模型可能更合适。
总而言之,目的是为了更好地理解模型、模型的训练过程、模型的可解释性以及不同模型之间的联系。
文章结构
从实践者的角度,通常将模型分为以下两类:监督学习和无监督学习。
对于监督学习,有回归和分类。对于无监督学习,有聚类和降维。
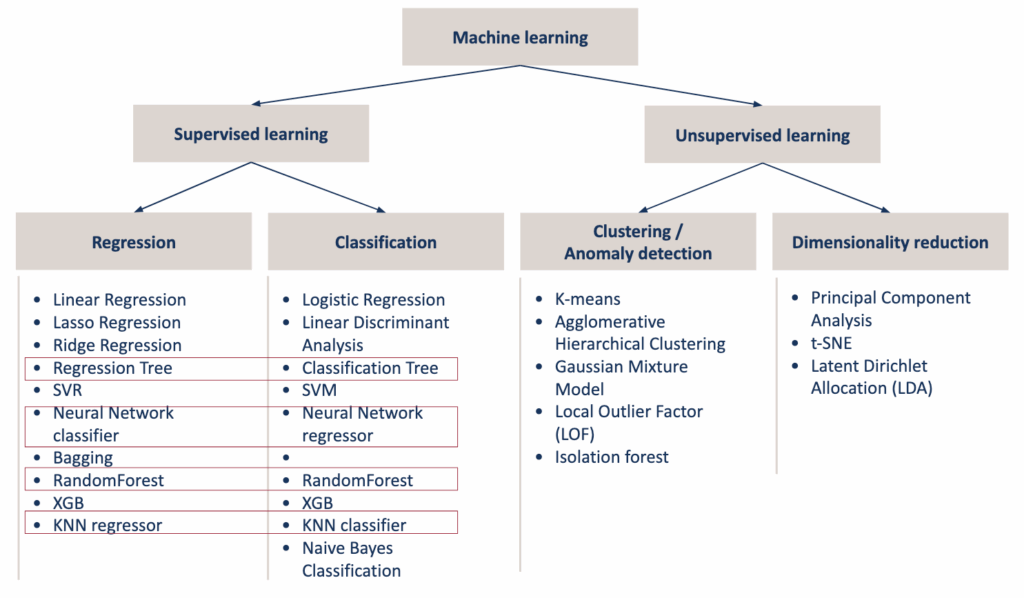
从实践者视角看机器学习模型概览 – 图片由作者提供
但肯定已经注意到,有些算法可能共享相同或相似的方法,例如KNN分类器与KNN回归器,决策树分类器与决策树回归器,线性回归与“线性分类器”。
回归树和线性回归有相同的目标,即执行回归任务。但当尝试在Excel中实现它们时,会发现回归树与分类树非常接近。而线性回归则更接近神经网络。
有时人们会混淆K-NN和K-means。有人可能认为它们的目标完全不同,混淆它们是初学者的错误。但是,也必须承认它们共享计算数据点之间距离的相同方法。因此它们之间存在关联。
孤立森林也是如此,可以看到随机森林中也存在“森林”。
因此,将从理论角度组织所有模型。主要有三种方法,并且将清晰地看到这些方法在Excel中以非常不同的方式实现。
这个概览将有助于导航所有不同的模型,并在许多模型之间建立联系。

按理论方法组织的机器学习模型概览 – 图片由作者提供
- 对于基于距离的模型,将计算新观测值与训练数据集之间的局部或全局距离。
- 对于基于树的模型,必须定义用于对特征进行分类的分割点或规则。
- 对于数学函数模型,核心思想是对特征应用权重。在训练模型时,主要使用梯度下降法。
- 对于深度学习模型,主要重点在于特征工程,以创建数据的适当表示。
对于每个模型,将尝试回答以下问题。
关于模型的一般性问题:
- 模型的本质是什么?
- 模型是如何训练的?
- 模型的超参数有哪些?
- 相同的模型方法如何用于回归、分类甚至聚类?
特征是如何建模的:
- 如何处理分类特征?
- 如何管理缺失值?
- 对于连续特征,缩放有影响吗?
- 如何衡量一个特征的重要性?
如何量化特征的重要性?这个问题也将被讨论。可能知道像LIME和SHAP这样的包非常流行,并且它们是模型无关的。但事实是,每个模型的行为都相当不同,直接通过模型进行解释也很有趣且重要。
不同模型之间的关系
每个模型将单独成文,但会讨论与其他模型的联系。
由于真正打开了每个“黑箱”,也将了解如何对某些模型进行理论改进。
- KNN和LDA(线性判别分析)非常接近。前者使用局部距离,后者使用全局距离。
- 梯度提升与梯度下降相同,只是向量空间不同。
- 线性回归也可以作为分类器。
- 标签编码可以用于分类特征,并且可能非常有用、非常强大,但必须明智地选择“标签”。
- SVM与线性回归非常接近,甚至更接近岭回归。
- LASSO和SVM使用一个相似的原理来选择特征或数据点。是否知道LASSO中的第二个S代表“选择”?
对于每个模型,还将讨论大多数传统课程会遗漏的一个特定点。这被称为机器学习模型的“未授之课”。
模型训练与超参数调优
在这些文章中,将只关注模型的工作原理和训练方式。不会讨论超参数调优,因为这个过程对于每个模型本质上是相同的。通常使用网格搜索。

文章列表
下方将提供一个列表,计划从12月1日开始,每天更新发布一篇文章!
敬请期待!
想了解 AI 如何助力您的企业?
免费获取企业 AI 成熟度诊断报告,发现转型机会
//
24小时热榜


热门标签
关注公众号

扫码关注,获取最新 AI 资讯
免费获取 AI 落地指南
3 步完成企业诊断,获取专属转型建议
已有 200+ 企业完成诊断